

We are helping hundreds of companies build secure applications















































Discover Continuous Hacking
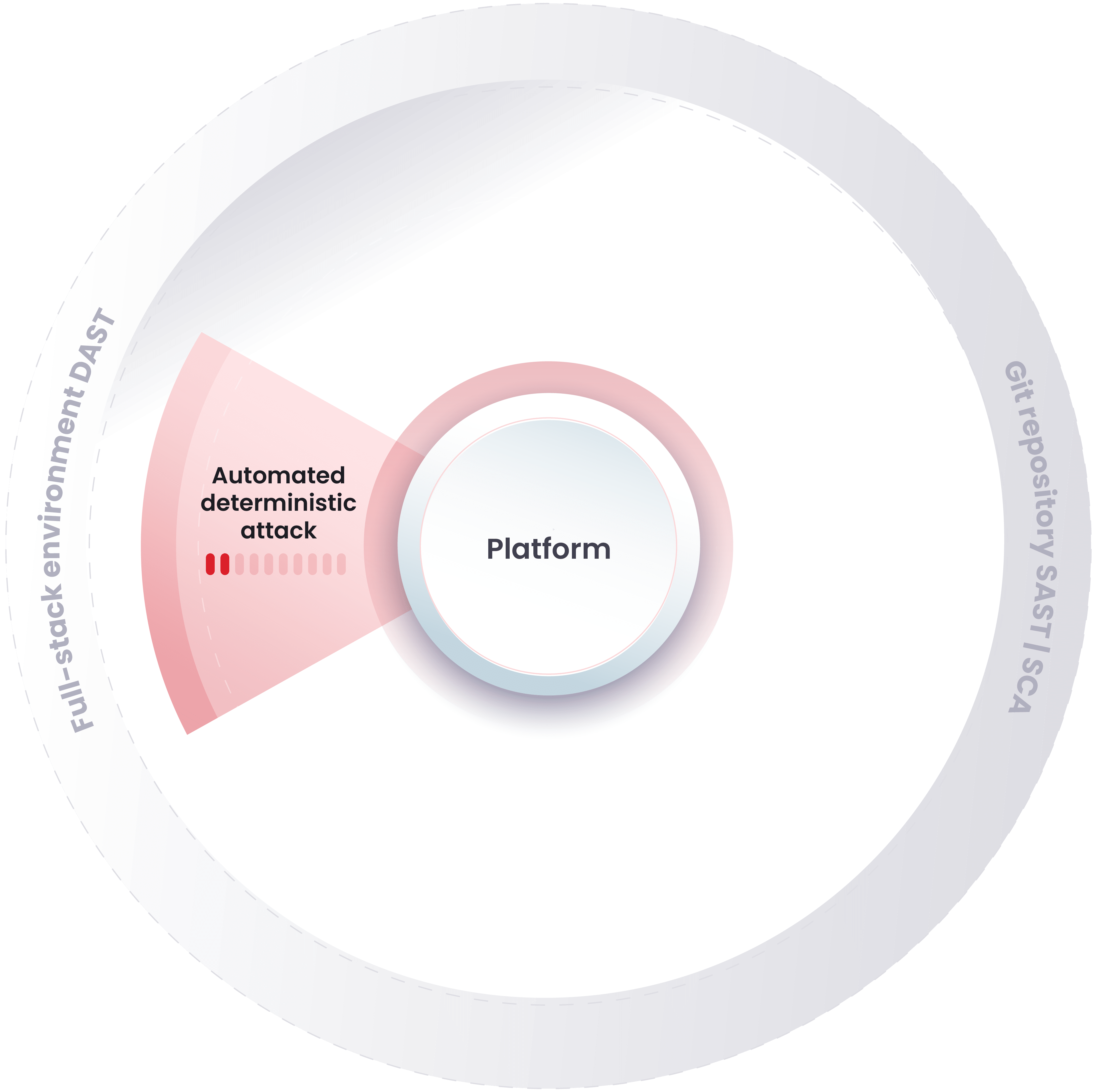
Fluid Attacks performs comprehensive security testing continuously

All-in-one approach
We combine automation, AI and expert intelligence to perform SAST, DAST, SCA, CSPM, SCR, MPT and RE. This way, we provide you with accurate knowledge of the security status of your application.

Fast and secure deployments
We enable your DevSecOps implementation. This means security goes alongside innovation without hindering your speed.

Support across your SDLC
We provide you with expert knowledge about vulnerabilities and support options that enable you to remediate the security issues in your application.
How does Continuous Hacking work?
We accurately detect vulnerabilities in continuous cycles as your technology evolves
Our automated analyses include SAST, DAST, SCA and CSPM. Our tools scan your system and report the common vulnerabilities, showing low false positive rates.
Our AI is specially trained with thousands of snippets of vulnerable code. A dedicated module helps us prioritize potentially vulnerable files for review.
Our highly certified red team continuously examines code, infrastructure and applications for security vulnerabilities through manual pentesting.
Our experts review the findings manually, discard potential false positives and assess the validity of results before showing them to your team.
Our experts seek to reduce false negatives by searching even deeper for vulnerabilities.
Our experts evaluate the effectiveness of your fix to a vulnerability and whether new vulnerabilities emerged due to the implementation.
Develop software knowing you are backed up by our powerful application security solutions
We help you optimally integrate security into development.
Solutions
DevSecOps
You can integrate security into your DevOps approach throughout your software development lifecycle to achieve the DevSecOps methodology.
Solutions
Secure Code Review
You can verify if your lines of code comply with various required standards and if there are security vulnerabilities you should remediate.
Solutions
Red Teaming
You can ask our red team to attack your company with its consent and reveal the flaws in its prevention, detection and response strategies.
Solutions
Security Testing
You can obtain accurate and detailed reports on security vulnerabilities in your IT infrastructure, applications and source code.
Solutions
Penetration Testing
You can have us perform continuous penetration testing, including simulated attacks on your systems, to discover vulnerabilities tools cannot find.
Solutions
Ethical Hacking
You can have our ethical hackers constantly search for and find what threat actors might exploit in your IT systems, outdoing other hacking services.
Solutions
Vulnerability Management
You can examine data on the identification, classification and prioritization of vulnerabilities in your systems.
Solutions
Application Security Posture Management
You can have us orchestrate our AST methods throughout your SDLC and correlate and prioritize findings in favor of your risk exposure management.
Solutions
Attack Resistance Management
You can manage and monitor your attack surface, the tests of your attack prevention, detection and response controls and the risks caused by flaws in them.
Solutions
DevSecOps
You can integrate security into your DevOps approach throughout your software development lifecycle to achieve the DevSecOps methodology.
Solutions
Secure Code Review
You can verify if your lines of code comply with various required standards and if there are security vulnerabilities you should remediate.
Solutions
Red Teaming
You can ask our red team to attack your company with its consent and reveal the flaws in its prevention, detection and response strategies.
Solutions
Security Testing
You can obtain accurate and detailed reports on security vulnerabilities in your IT infrastructure, applications and source code.
Solutions
Penetration Testing
You can have us perform continuous penetration testing, including simulated attacks on your systems, to discover vulnerabilities tools cannot find.
Solutions
Ethical Hacking
You can have our ethical hackers constantly search for and find what threat actors might exploit in your IT systems, outdoing other hacking services.
Solutions
Vulnerability Management
You can examine data on the identification, classification and prioritization of vulnerabilities in your systems.
Solutions
Application Security Posture Management
You can have us orchestrate our AST methods throughout your SDLC and correlate and prioritize findings in favor of your risk exposure management.
Solutions
Attack Resistance Management
You can manage and monitor your attack surface, the tests of your attack prevention, detection and response controls and the risks caused by flaws in them.
Our clients deploy secure technology several times daily. When will you start?
Learn how Continuous Hacking helps our clients keep their applications secure.

SUCCESS STORY
Fluid Attacks' Continuous Hacking helps Payválida identify vulnerabilities in their application at the speed of their business.
SUCCESS STORY
Fluid Attacks' Continuous Hacking helps Protección find out the risks to its applications during development so it can prevent security incidents.
