Philosophy
From flaky to bulletproof: Our new testing architecture for software development


Staff Engineer
9 min
At Fluid Attacks, we have been building and maintaining our platform for almost 5 years now. The path to developing a world-class platform that empowers both hackers and developers to make more secure software has been full of learnings that could not be put in a single blog post, as they even shaped Fluid Attacks' engineering team's identity and philosophy.
With quality being one of our main concerns, we’re constantly asking ourselves, "How can we make an application that is being deployed to production more than 40 times a day by a team of over 20 developers behave as expected and be easy to test?"
This simple question brings a considerable amount of complexity to the table and, of course, more questions:
Can we approach tests in a standard way to increase maintainability?
What types of tests should we use for our application?
How can we make testing comfortable for developers?
Can we force developers to maintain a certain percentage of code coverage?
Teams can feel overwhelmed as more questions appear; this is because testing is an elemental part of building and maintaining an application, and decisions made around it will eventually affect everything else, including the following:
Whether or not the application does what it is supposed to do.
The mean time to production, or how long it takes for a developer to reach production.
The development experience, or how easy it is for developers to test expected behavior on the application.
CI/CD costs and time, as application pipelines are mostly composed of such tests.
If you are looking for inspiration to build your own testing approach or just want to expand your knowledge, stay with us. We'll talk about our platform, the testing architectures we previously used — along with pain points — how we evolved to a faster and more reliable architecture, and the conclusions we've drawn from this endeavor.
As the technical complexity of this blog post is of an intermediate-high level, we recommend having a basic understanding of the following:
Fluid Attacks' platform's basic nature
These are the most important things to consider regarding Fluid Attacks' platform:
It is a monolithic webserver written in Python.
It serves an API.
It uses AWS DynamoDB as its primary database.
Its source code can be found in Fluid Attacks' Universe repository.
Previous testing architectures and their pain points
Unit tests
This was the first testing approach we used. It came about due to the basic need for testing, so it did not go through a design phase. Here's a high-level diagram describing it:
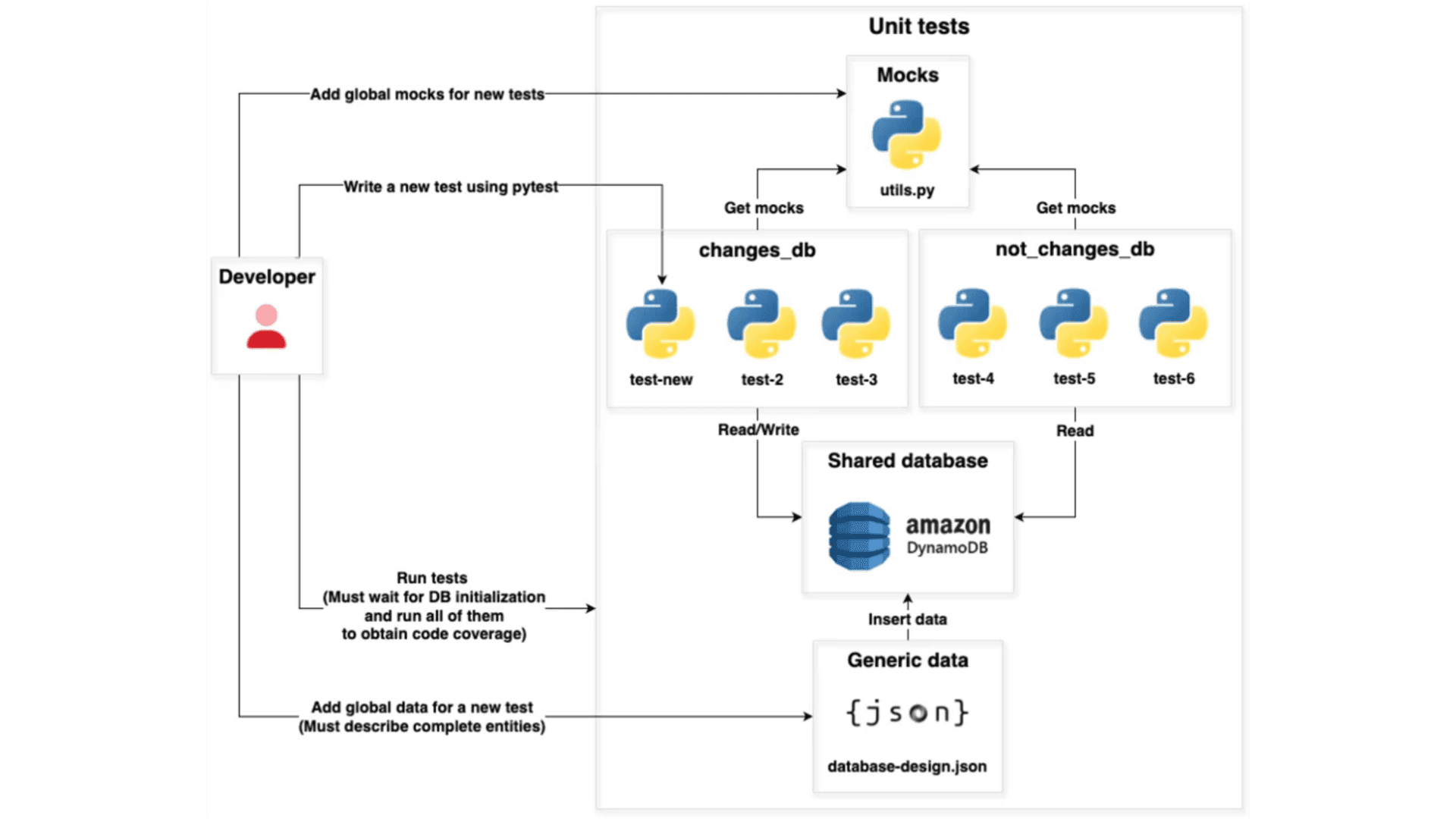
All tests used a global utils.py file for mocking, which proved to be very hard to maintain as it grew. Moreover, the tests were challenging to comprehend because the mocks happened somewhere else.
The tests existed in a separate directory from the application source code. While the latter was located in
integrates/back/integrates, the test code was found inintegrates/back/test/unit. This affected our development experience, as it forced us to switch between two different directories constantly.Tests were written using pytest. This allowed developers to write tests in many different ways, affecting standardization and increasing cognitive load.
All tests shared a common DynamoDB database that ran on localhost and got its data from a database-design.json file. This introduced flakiness as sometimes some tests changed data that others used, causing the latter to fail. Furthermore, this localhost dependency significantly affected testing speed due to slow database initialization.
The database-design.json file grew too large and became difficult to maintain, as nobody knew if specific data was actually used in testing.
The database-design.json file forced developers to describe entire database entities rather than just the attributes they cared for in a given test, making data declaration unnecessarily complex.
As an attempt to mitigate flakiness introduced by all tests sharing a common database, tests were divided into two categories:
changes_db: Tests that read and wrote DynamoDB
not_changes_db: Tests that only read DynamoDB
This approach managed to deal with flakiness to a certain extent, as at least tests that did not change the database were separated. However, it did not fix the root cause: tests sharing data.
Developers had to wait for the entire test suite to finish before knowing the code coverage. This was especially painful due to the fact that the CI/CD pipeline failed if coverage was lower than a specified threshold, but developers could only validate this after running everything.
Tests were able to connect to the Internet and communicate with external services, which introduced more flakiness.
In short, these tests were:
Hard to understand and replicate due to too much freedom given to developers and having global mocks and data.
Slow due to database initialization and forcing developers to run the entire test suite to know code coverage.
Flaky due to data being shared by tests globally.
For these reasons, most developers avoided these tests as much as they could and instead focused on the types we see below.
The source code for the unit tests can be found here.
Functional tests
The second architecture was built thinking about the main problems we found in the previous one but focusing on finding a way to test API endpoints. Here's a high-level diagram describing it:

As there was one test per API endpoint, we quickly ended up having hundreds of tests, which caused the CI/CD pipeline to grow too large and costs to rise.
Mocks stopped being global, forcing developers to write specific mocks for each test. This improved test simplicity and maintainability.
The tests existed in a separate directory from the application source code. While the latter was located in
integrates/back/integrates, the test code was found inintegrates/back/test/functional. This affected our development experience, as it forced us to switch between two different directories constantly.Tests were written using pytest. This allowed developers to write tests in many different ways, affecting standardization and increasing cognitive load.
DynamoDB became local to each test, meaning that flakiness caused by tests modifying data used by others went away.
Although each test had its own database during runtime, all shared generic data in a conftest.py file. This caused flakiness, as one test could adapt generic data according to its specific needs and thus break down other tests.
Generic data still forced developers to describe entire database entities rather than just the attributes they cared for in a given test, making data declaration unnecessarily complex.
Tests still required DynamoDB to run on localhost, highly affecting speed due to database initialization.
As the number of tests grew, having each test use its own DynamoDB on localhost considerably increased the total amount of time we spent initializing and populating databases, which significantly reduced speed and raised CI/CD pipeline costs.
Because DynamoDB was bound to a port on localhost, only one database could work at a given time, forcing developers to run only one test at a time, greatly reducing the team's speed.
Tests could connect to the Internet and communicate with external services, which introduced more flakiness.
Developers had to wait for the entire test suite to finish to know the coverage. It got even worse as tests, which might number in the hundreds, could not be executed concurrently. The impact was deep, as knowing the coverage locally became impossible (running hundreds of tests sequentially took longer than 10 hours).
In short, these tests, in comparison with the unit tests, were:
Easier to understand, as each test had local mocks and was focused on a specific API endpoint.
Less flaky, as each test had its own database.
Slower, as they could not be executed concurrently.
Developers still preferred functional tests over unit tests due to their simplicity and reduced flakiness.
The source code for the functional tests can be found here.
A new testing architecture
After years of struggling with the two previous testing designs, we found several common pain points:
Tests existed in a separate directory from the application source code, affecting developers' experience.
Tests were hard to understand because pytest gave too much freedom to developers.
Tests were flaky due to race conditions caused by shared testing data and having Internet access.
Providing data for a given test was too complex as complete database entities had to be described, making developers copy-paste entire data sections rather than creating specific data for each test.
Both architectures were very slow because they had to turn on databases.
Both architectures required developers to run the whole suite before knowing the resulting code coverage.
With these pain points in mind, we focused on implementing a new approach that would allow us to replace unit and functional tests. After two months of iteration, we came up with a new, standard architecture that addressed every issue described above. Here's a high-level diagram describing it:
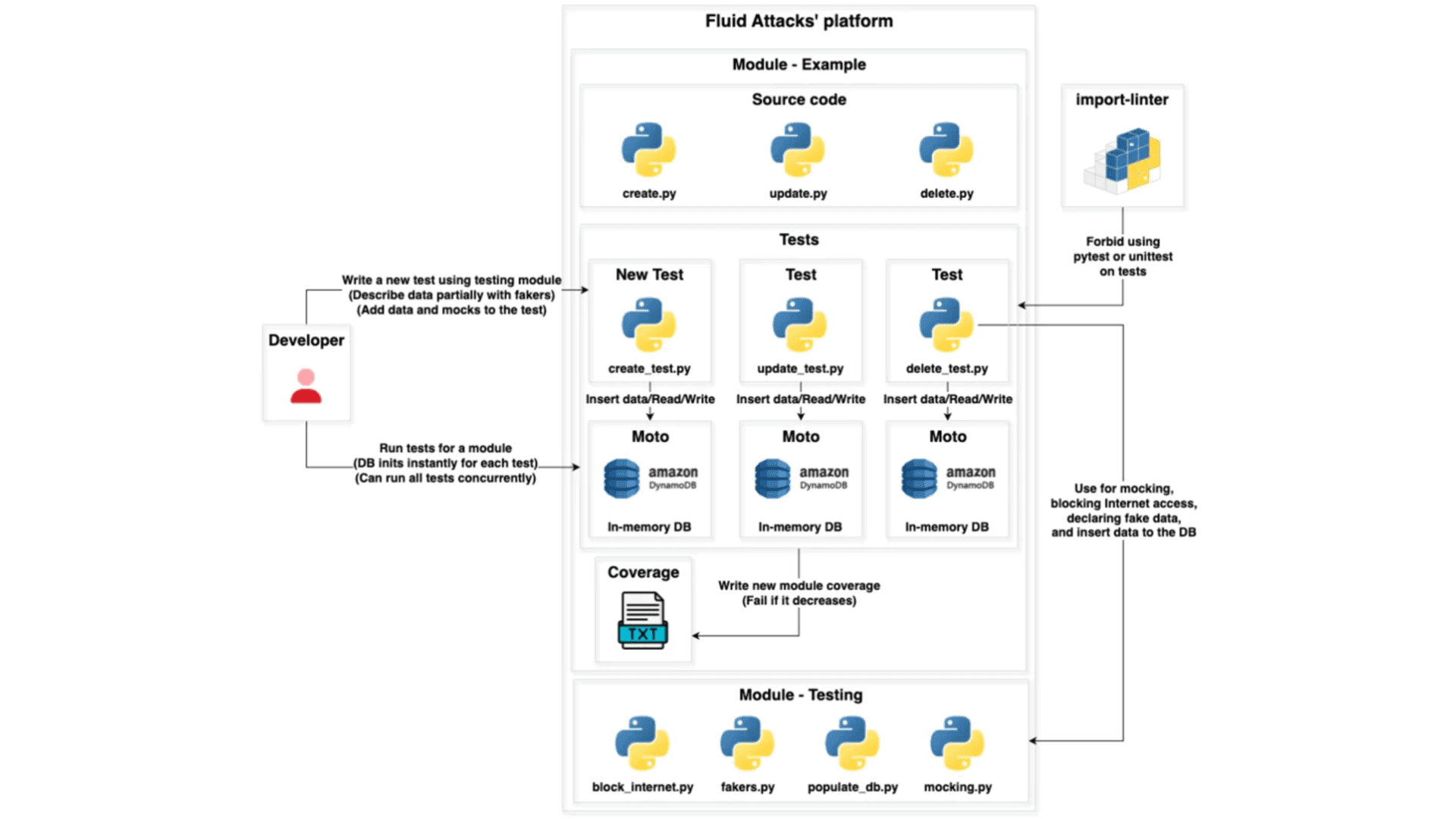
The tests are in the same directory as the application source code, which improves the development experience by allowing us to easily find the tests for specific files or functions. This also empowers developers to adopt best practices such as Test Driven Development (TDD).
Developers can write tests for anything, including specific functions and API endpoints. Therefore, we can migrate all tests from previous architectures to this one.
It implements a testing module that standardizes how we write tests, which are considerably easier to understand when following common patterns.
Using import-linter forbids developers from importing libraries like pytest and unittest, forcing them to use only utilities provided by the testing module. This significantly increases test standardization.
It implements fakers so developers can partially describe database entities, making declaring data for each test much more comfortable and improving the developers' experience.
Tests are no longer able to connect to the Internet and communicate with external services, avoiding flakiness.
It provides a standard, declarative way for developers to add data to tests, improving their experience.
It gives developers a way to easily declare mocks within tests, making them easier to understand.
It implements Moto, a library that allows the simulation of AWS services like DynamoDB. This makes tests run rocket-fast by instantiating an in-memory DynamoDB database within the Python context of each test.
As databases exist within the Python context, they are no longer bound to a localhost port, allowing developers to run tests concurrently, further increasing speed.
It introduces a coverage file for each module within the application, allowing developers to concurrently run all tests for a given module and instantly know code coverage results, greatly improving the development experience and speed.
It decreases the CI/CD pipeline size by moving from a one-job-per-test to a one-job-per-module approach, considerably reducing CI/CD costs.
In short, when compared to the previous ones, the new testing architecture is:
Closer to the application source code, improving the developers' experience.
Standard, as developers must use the testing module specially designed for our needs.
Flexible, as it allows developers to test anything within the application.
Fast, because it uses Moto for databases and tests can be executed concurrently.
Less flaky, as each test uses its own data and mocks and cannot connect to the Internet.
Scalable, as the number of CI/CD jobs equals the number of modules within the application.
The source code for these tests can be found here (notice this is the application source code directory, as mentioned previously).
More technical information regarding the new architecture can be found here.
Conclusions
These conclusions can help you a lot when deciding how to test your applications:
Make your tests coexist with the application code, as this empowers developers to adopt good practices like TDD and improves navigation.
If you are building a big application that will need hundreds of tests, instead of using general-purpose testing libraries like pytest or unittest directly, focus on creating your own testing approach that reuses critical functionalities from those libraries (e.g., a wrapper or a testing module). Then, use import-linter to force developers to employ that approach. This will ensure that your tests remain consistent and considerably help developers maintain them in the long term.
Use libraries that mock core services, such as Moto, instead of serving those components on localhost so that tests run much faster.
Avoid global states for your tests as much as possible (data, mocks, etc.), as they introduce flakiness. Use libraries like Moto to provide a local state for each test.
Forbid your tests from reaching the Internet in order to avoid flakiness.
If you're implementing strict policies for code coverage, make sure developers can validate it locally as comfortably as possible.
What's next
There are several things we'll do in the future concerning our new testing architecture:
Migrate all tests from our previous architectures to this one in order to deprecate old flows and keep things simple. More information about it can be found here.
Make this architecture support other critical components for the monolith, such as AWS S3, AWS OpenSearch and AWS lambda. This way, developers will be able to easily mock other parts of the monolith while keeping all the benefits of the current architecture. More details here.
This architecture was made specifically for Fluid Attacks' platform's monolith, so it is coupled to it, which stops us from using it in other applications that might benefit from some of its properties. One of the things we plan to do in the long term is decoupling Fluid Attacks' data model from the monolith so that other applications can use it as well. The first step we'll take in that direction is described here.
Special thanks
Lastly, I would like to give a warm thank you to everyone who believed in this project:
Juan Restrepo, for empowering the team to discover new and better ways to do things.
Daniel Betancur and Juan Echeverri, for always being there when we needed something to keep moving forward.
Juan Diaz, for implementing core parts of the new architecture like CLI, fakers, Moto, etc.
Brandon Lotero, for implementing database types.
David Acevedo, for implementing import-linter rules and Internet blocking.
Felipe Ruiz, for all the support in editing, translating and publishing this blog post.
Fluid Attacks' engineering team, for their support and feedback.

Get started with Fluid Attacks' ASPM solution right now
Other posts
























