Filosofía
El Protocolo de Contexto del Modelo (MCP): arquitectura, riesgos de seguridad y mejores prácticas


Escritor y editor
9 min
El Protocolo de Contexto del Modelo (MCP) se está estableciendo rápidamente como un componente fundamental en la arquitectura de los sistemas de IA avanzados, especialmente para las aplicaciones de IA agéntica que necesitan acceder dinámicamente a fuentes de datos externas, herramientas y flujos de trabajo. Desarrollado y publicado como código abierto a finales de 2024 por Anthropic, el objetivo del MCP es resolver el problema del aislamiento de la IA al ofrecer un estándar abierto y universal que conecte a los grandes modelos de lenguaje (LLM) con los sistemas empresariales y de desarrollo clave donde reside información relevante.
Sin embargo, esta potente capa de abstracción también introduce nuevos y significativos riesgos de seguridad al crear vías dinámicas entre los agentes de IA y la infraestructura central de TI. Por lo tanto, proteger el MCP es crucial para las organizaciones que buscan aprovechar el poder de la automatización impulsada por la IA.
Comprendiendo el MCP
El MCP es un estándar de código abierto que posibilita la comunicación segura y bidireccional entre las aplicaciones de IA (los clientes) y los sistemas externos (los servidores). Su función es similar a la de un conector universal o un "puerto USB-C para la IA", eliminando la necesidad de integraciones rígidas y personalizadas para cada nueva fuente de datos o herramienta.
De la fragmentación a la estandarización
Antes del MCP, para conectar un LLM a sistemas dispares (p. ej., un repositorio de Google Drive, un canal de Slack o una base de datos PostgreSQL) se requería la creación de integraciones de API separadas y ad hoc para cada uno. Este enfoque fragmentado dificultaba la escalabilidad y el mantenimiento. El MCP aborda este desafío proporcionando una especificación unificada, lo que permite a los desarrolladores construir sobre un único protocolo estandarizado. Esta estandarización reduce drásticamente las barreras de integración, permitiendo que los modelos de IA mantengan un contexto enriquecido a lo largo de múltiples interacciones y ejecuten acciones conscientes del contexto en favor del usuario.
Arquitectura básica: modelo cliente-servidor
El MCP se rige por una arquitectura cliente-servidor simple y clara:
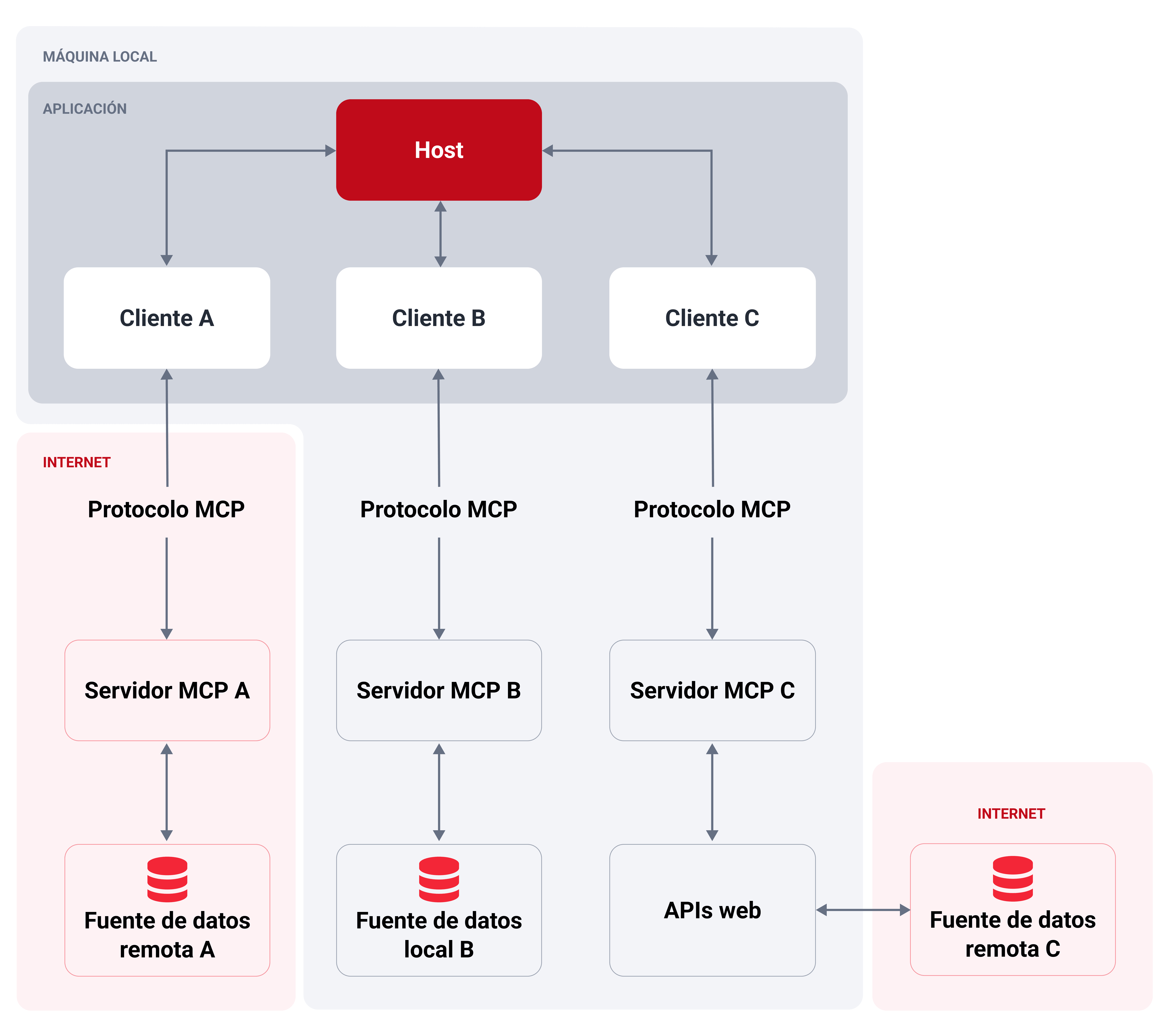
Diagrama de arquitectura MCP que ilustra tres flujos diferentes.
Host MCP: Es la aplicación o entorno con el que interactúa el usuario (p. ej., un IDE impulsado por IA, un chatbot empresarial personalizado o una aplicación de escritorio como Claude Desktop). El host (anfitrión) gestiona la experiencia del usuario y ejecuta el modelo de IA.
Cliente MCP: Es un componente instanciado por la aplicación host que gestiona la conexión dedicada y la comunicación uno a uno con un servidor MCP. Actúa como el intermediario que traduce la intención de la IA en solicitudes a nivel de protocolo para el servidor y retransmite los resultados de vuelta.
Servidor MCP: Es un servicio externo —a menudo un proceso local o una API remota— que expone capacidades específicas (herramientas, recursos y prompts) a la aplicación de IA a través del protocolo MCP. Los servidores se pueden construir para conectar con sistemas de archivos y bases de datos, así como servicios en la nube y plataformas de control de versiones como GitHub y GitLab, entre otras cosas.
Las tres primitivas: herramientas, recursos y prompts
El núcleo del MCP es la capa de datos, definida por tres primitivas fundamentales que los servidores MCP pueden exponer a los clientes:
Primitiva | Descripción | Mecanismo de control | Ejemplos de funcionalidad |
Herramientas | Funciones ejecutables que la aplicación de IA puede invocar para realizar acciones con entradas y salidas definidas. | Controladas por el modelo (la IA decide cuándo y cómo invocarlas basándose en la solicitud del usuario). | Buscar vuelos; enviar mensajes; modificar un archivo; ejecutar una consulta en una base de datos. |
Recursos | Fuentes de datos pasivas que proporcionan información contextual de solo lectura. | Controladas por la aplicación (el cliente decide qué información recuperar y cómo presentarla como contexto al modelo). | Recuperar el contenido de documentos; acceder a esquemas de bases de datos; leer documentación de API; obtener entradas de calendario. |
Prompts | Plantillas estructuradas y reutilizables que guían o estructuran las interacciones con el LLM. Pueden hacer referencia a herramientas y recursos disponibles. | Controladas por el usuario (requieren invocación explícita, a menudo mediante comandos de barra inclinada o botones dedicados). | Plantilla "/entregar-reporte-vulnerabilidades"; prompt de sistema "Resumir mis reuniones". |
Riesgos de seguridad del MCP
La capacidad de integración que hace que el MCP sea tan potente es también su principal preocupación de seguridad. Al crear vías dinámicas y directas entre los modelos de IA (el nuevo plano de control) y los sistemas empresariales sensibles, el MCP elimina efectivamente las fronteras de seguridad tradicionales que dependen del aislamiento del sistema. Un solo servidor MCP comprometido puede llevar a una violación de múltiples sistemas de alto valor.
Riesgos de la cadena de suministro e integridad
Debido a que cualquier persona puede desarrollar y distribuir servidores MCP, y muchos operan con privilegios elevados, se convierten en objetivos de alto valor para los ataques a la cadena de suministro.
Servidores maliciosos o envenenados: Los atacantes pueden distribuir servidores falsos a través de repositorios públicos, como GitHub o PyPI, con nombres engañosamente similares a los legítimos (esto es, colisión de nombres o typosquatting). Una vez instalados, estos servidores pueden contener puertas traseras, exfiltrar datos o ejecutar código arbitrario con los mismos privilegios que el usuario o la aplicación anfitriona (host).
Suplantación del instalador/código: La instalación de un servidor MCP local a menudo implica la ejecución de scripts, lo que representa una oportunidad para que los atacantes inyecten malware o instaladores manipulados.
Dependencias no auditadas: Los servidores MCP son básicamente paquetes de software que dependen de librerías upstream. Un compromiso en una de estas dependencias puede introducir vulnerabilidades en la base de código del servidor (inyección de código o puertas traseras).
Fallas de autorización y autenticación
El MCP utiliza las convenciones de OAuth para la autorización, pero los errores de implementación pueden generar vulnerabilidades críticas de identidad y acceso.
Ataques de diputado confundido (secuestro de tokens): Es una vulnerabilidad de flujo de OAuth específica que afecta a los servidores proxy de MCP (servidores que actúan como una puerta de enlace a una API de terceros). Un atacante puede explotar la combinación de IDs de cliente estáticos y el registro dinámico de clientes para engañar a un usuario a que conceda un código de autorización que luego se redirige al servidor del atacante, lo que permite robar tokens de acceso y suplantar al usuario.
Token passthrough (anti-patrón): Es una práctica explícitamente prohibida donde un servidor MCP acepta un token de acceso del cliente MCP y lo pasa directamente a la API downstream sin validar que el token haya sido emitido específicamente para el servidor MCP. Esto elude controles de seguridad esenciales, como la limitación de tasa y la validación de la audiencia, y dificulta la auditoría.
Alcances con exceso de privilegios y fuga de credenciales: Los servidores MCP solicitan frecuentemente alcances de permiso amplios (p. ej., acceso completo de lectura/escritura a Gmail y Google Drive) por conveniencia. Esta centralización de múltiples tokens altamente sensibles (p. ej., claves API, tokens OAuth) implica que un compromiso de un solo servidor puede resultar en un radio de explosión masivo en todo el ecosistema conectado y en la fuga de información confidencial.
Ataques de manipulación de herramientas y agentes
Estos ataques aprovechan la dependencia de la IA en las primitivas (herramientas, recursos y prompts) para lograr fines maliciosos, a menudo explotando la lógica interna del agente.
Inyección de prompts y envenenamiento de herramientas: Se pueden ocultar instrucciones maliciosas en la entrada del usuario, en la descripción/documentación de la herramienta o en el contenido de un recurso. El LLM entonces interpreta estos comandos ocultos como instrucciones legítimas, lo que lo lleva a realizar acciones no autorizadas, tales como:
Exfiltrar datos sensibles (p. ej., enviar claves SSH a través de una herramienta legítima "send_email")
Modificar registros de bases de datos
Escribir código inseguro
Fuga de contexto: Dado que el agente de IA comparte partes de la conversación, el estado y los datos de los recursos con las herramientas conectadas para mantener el contexto, un servidor no confiable o malicioso podría acceder a información sensible destinada a otra herramienta o solo al usuario.
Ataques de sombra entre servidores: En un entorno con múltiples servidores MCP conectados, un servidor malicioso puede registrar herramientas con nombres iguales o muy similares a los de las herramientas de un servidor legítimo y confiable (p. ej., dos comandos "delete" diferentes). El modelo de IA puede invocar erróneamente la herramienta maliciosa, resultando en acciones no autorizadas e incluso pérdida de datos.
Riesgos de ejecución local y aislamiento (servidores MCP locales)
Los servidores MCP locales, los cuales se ejecutan en la máquina del usuario (a menudo con los mismos privilegios que el usuario o la aplicación cliente), introducen riesgos importantes a nivel de sistema.
Ejecución de código arbitrario y escape de sandbox: Si un atacante puede inyectar instrucciones maliciosas en el comando de un servidor local, puede ejecutar cualquier comando en la máquina anfitriona. Si el servidor no está debidamente aislado (sandboxed; p. ej., en un contenedor o un entorno restringido), un compromiso exitoso puede conducir a un escape del sandbox y a un movimiento lateral a través de la máquina anfitriona e incluso la red interna.
DNS rebinding: Un atacante puede acceder a un servidor local inseguro que se ejecuta en "localhost" a través de JavaScript comprometido, lo que lleva a la exfiltración de datos o acciones no autorizadas.
Mejores prácticas de seguridad para el MCP
Proteger el MCP requiere un cambio de las defensas tradicionales centradas en la red a un modelo de plano de control consciente de la identidad y el contexto. Las siguientes mejores prácticas, extraídas de los estándares de la comunidad y la investigación de seguridad, son cruciales para mitigar los riesgos del MCP.
Verificación de servidores y seguridad de la cadena de suministro
Trata a cada servidor MCP y sus dependencias como software privilegiado que puede acceder a tus sistemas más críticos.
Establecer un registro de confianza: Mantén un inventario interno de servidores MCP aprobados y sus versiones verificadas. Permite solamente la instalación desde esta lista preaprobada.
Veto y controles de seguridad: Implementa revisiones de seguridad rigurosas, análisis estático (SAST) y análisis de composición de software (SCA) para todo el código de los servidores y sus dependencias antes del despliegue.
Verificación criptográfica: Obliga al uso de paquetes firmados y controles de integridad (checksums/firmas) para asegurar que el código que se ejecuta es la versión oficial y no ha sido manipulado.
Fijar versiones: Configura los clientes MCP para fijar las versiones de las herramientas y evitar cambios inesperados en el comportamiento o regresiones de seguridad derivadas de actualizaciones automáticas. Realiza un seguimiento del servidor ascendente en busca de parches y revísalos antes de desplegarlos.
Autenticación y principio de mínimo privilegio
Aplica controles estrictos sobre quién puede conectarse a un servidor y qué acciones puede realizar el modelo en su nombre.
Alcance estricto de los tokens: Haz cumplir el principio de mínimo privilegio para todas las claves API y tokens OAuth utilizados por los servidores MCP. Emite tokens de corta duración y alcance mínimo. Cada servidor debe tener solo los permisos necesarios para su funcionalidad prevista (p. ej., un servidor de lectura de archivos no debe tener permisos de escritura en la base de datos).
Prohibir el token passthrough: Tus servidores MCP no deben aceptar o pasar tokens que no fueron emitidos explícitamente para sus propios servicios (validando la audiencia del token).
Mitigar ataques de diputado confundido: Tus servidores proxy de MCP deben implementar un consentimiento por cliente y controles de seguridad adecuados:
Conservar un registro de los valores "client_id" aprobados por usuario
Implementar protección CSRF (cross-site request forgery) en la página de consentimiento a nivel de MCP
Prevenir el clickjacking deshabilitando el iframing
Evitar la autenticación basada en sesiones: Tus servidores MCP no deben utilizar IDs de sesión para la autenticación. Todas las solicitudes entrantes que implementen autorización deben ser verificadas contra un token válido y vinculado al usuario.
Validación de entradas y barreras de herramientas
Implementa barreras sólidas para prevenir la manipulación del modelo y proteger el sistema anfitrión.
Validar rigurosamente las entradas: Todos los parámetros pasados a las herramientas MCP deben ser validados contra su esquema (caracteres permitidos, longitud, formato). Si una herramienta ejecuta comandos del sistema, utiliza APIs seguras o comandos parametrizados en lugar de la concatenación de shell para prevenir la inyección de comandos.
Sanear salidas y descripciones: Sanea las descripciones y salidas de las herramientas antes de pasarlas de nuevo al contexto del LLM. Elimina o codifica cualquier markup o carácter complejo que el agente de IA pueda interpretar como instrucción maliciosa.
Aislar el contexto: Implementa el aislamiento del contexto para que cada servidor/herramienta solo reciba la mínima información necesaria para su operación, evitando que los datos sensibles se filtren a un componente no confiable.
Human-in-the-loop (consentimiento): Requiere confirmación explícita del usuario para cualquier acción de alto riesgo o destructiva (p. ej., ejecutar un comando, modificar datos o enviar una comunicación externa). La interfaz de usuario del cliente debería mostrar claramente la herramienta, la acción y los parámetros antes de solicitar la aprobación.
Seguridad operacional y del entorno
Asegúrate de que la infraestructura que ejecuta tus componentes MCP esté reforzada y sea monitoreada.
Sandboxing y aislamiento: Ejecuta todos tus servidores MCP locales y sus herramientas en un entorno sandboxed con privilegios mínimos por defecto. Utiliza contenedores, chroot o sandboxes a nivel del sistema operativo para contener cualquier daño en caso de compromiso.
Usar mTLS para la seguridad del transporte: Implementa TLS mutuo (mTLS) para todas las comunicaciones entre el cliente y el servidor MCP (si se ejecutan remotamente) para asegurar que ambas partes estén autenticadas y que el tráfico esté cifrado, previniendo espionaje o suplantación.
Política de "fallar cerrado": Si un servidor MCP o una dependencia requerida, como un servicio de identidad, deja de estar disponible, el sistema debe "fallar cerrado" (detener su funcionamiento) en lugar de "fallar abierto" (continuar operando con los controles de seguridad deshabilitados).
Registro y monitoreo exhaustivos: Habilita el registro detallado de cada interacción con tu MCP —qué herramienta fue invocada, por quién, con qué parámetros y cuál fue el resultado. Integra estos registros con un sistema SIEM (gestión de eventos e información de seguridad) para detectar patrones sospechosos, como múltiples intentos fallidos de selección de herramientas o recuperación excesiva de datos.
Ejemplo de implementación del MCP en Fluid Attacks
En Fluid Attacks, el Protocolo de Contexto del Modelo es fundamental para el componente "Interacts", que funciona como un potente agente de IA ofrecido a los clientes para la gestión de vulnerabilidades y el análisis de seguridad. Interacts es un servidor MCP construido utilizando Pydantic AI (un framework que enfatiza la entrada/salida predecible y validada) para proporcionar un acceso seguro y estructurado a los datos dentro de la plataforma de Fluid Attacks.
Visión general de la arquitectura
El diagrama de arquitectura proporcionado ilustra cómo Fluid Attacks aprovecha MCP para integrar capacidades de IA de forma segura:
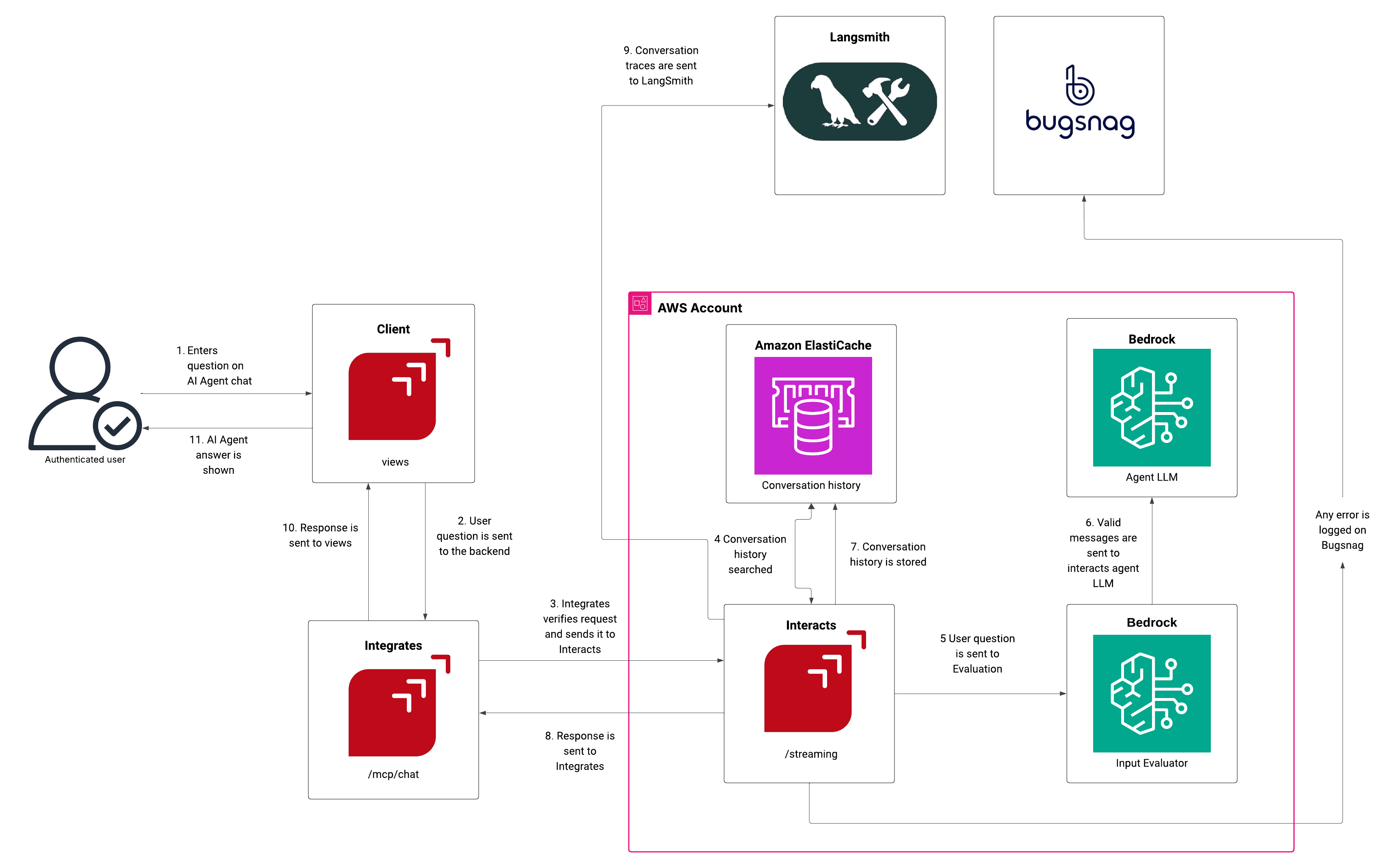
Solicitud del cliente: Un usuario autenticado introduce una pregunta en el chat del AI Agent del Cliente (componente "views").
Enrutamiento de la solicitud: La solicitud se envía al backend de Integrates (la plataforma de gestión de vulnerabilidades), que verifica la autenticación y reenvía la solicitud al componente Interacts (servidor MCP) en el punto final "/streaming".
Contexto y procesamiento de IA:
Interacts consulta Amazon ElastiCache para obtener el historial de conversaciones relevante y mantener la continuidad.
La pregunta se envía para evaluación a un componente Bedrock (Input Evaluator) y luego a otro (Agent LLM), que genera la respuesta de IA basada en la pregunta del usuario y el historial de conversación.
Seguridad y registro: Los rastros de la conversación se envían a LangSmith para su supervisión y depuración. Cualquier error se registra en BugSnag.
Entrega de la respuesta: La respuesta validada se envía de vuelta desde Interacts a Integrates y, finalmente, se muestra al usuario a través del Cliente (views).
Actualización del historial: El historial de conversaciones actualizado se vuelve a almacenar en Amazon ElastiCache.
Características clave de seguridad y capacidad
El servidor MCP de Fluid Attacks está diseñado con seguridad y un alcance mínimo en mente:
Característica | Descripción e implicaciones de seguridad |
Pydantic AI | Utiliza un marco de agentes basado en Python y seguro en cuanto a tipos, que promueve entradas y salidas predecibles y validadas, lo que ayuda a reducir el riesgo de comportamientos inesperados o fallas de inyección relacionados con los tipos de datos. |
Uso de Guardrails de Amazon Bedrock | Una defensa de múltiples capas que evalúa de forma proactiva las entradas de los usuarios y las salidas del modelo en busca de contenido inseguro, ataques de prompts e infracciones de políticas, proporcionando una verificación crucial antes de la invocación de herramientas. |
API token requerido | Todas las interacciones requieren un token API válido, lo que impone una autenticación sólida y vincula las acciones del agente de IA a una identidad de usuario autenticada específica. |
Capacidades de solo lectura | El servidor tiene solo capacidades de lectura (p. ej., recuperar datos de vulnerabilidades, organizaciones y análisis) y no puede modificar ni crear nada en la plataforma. Esto aplica el principio de mínimo privilegio y limita drásticamente el radio de acción de cualquier compromiso. |
Funciones soportadas | Las herramientas se limitan estrictamente a funciones básicas como gestión de vulnerabilidades (obtención y análisis), información sobre la organización, análisis e integración de GraphQL (ejecución de consultas). |
Al implementar estas medidas de seguridad, además de continuamente poner a prueba todo su software con SAST, SCA, revisión de código seguro, entre otras técnicas de pruebas de seguridad, Fluid Attacks minimiza los riesgos inherentes al framework MCP mientras maximiza la utilidad de un asistente de IA agéntica en beneficio de sus clientes.
Conclusión
El Protocolo de Contexto del Modelo representa una evolución crucial en la IA, transformando los LLM aislados en agentes dinámicos y conscientes del contexto, capaces de operar en complejos entornos empresariales. Si bien esta transición acelera la automatización, eleva simultáneamente la necesidad de un modelo de seguridad proactivo y centrado en la identidad que vaya más allá de las defensas perimetrales tradicionales. Adoptar las mejores prácticas recomendadas, desde la estricta verificación de la cadena de suministro hasta los controles human-in-the-loop, es primordial para asegurar el plano de control de la IA agéntica y aprovechar de manera segura todo el potencial del MCP.
En caso de necesitar ayuda con la evaluación de la seguridad y la mitigación de riesgos en tus entornos y productos potenciados por IA, no dudes en contactarnos.

Empieza ya con la solución de seguridad de IA de Fluid Attacks
Suscríbete a nuestro boletín
Mantente al día sobre nuestros próximos eventos y los últimos blog posts, advisories y otros recursos interesantes.
Otros posts

























