Development
Claude Code shows that AI agents are more engineering than magic


Content writer and editor
11 min
A description of how Claude Code works, such as this one, might still sound like science fiction to some people: you give the system a task, and it reads your codebase, edits files, runs commands, calls external tools, delegates work to subagents, keeps track of the context, and checks whether its own changes actually worked. Anthropic's documentation, meanwhile, presents Claude Code more succinctly as an agentic coding tool that reads a codebase, edits files, runs commands, and integrates with development tools across the terminal, IDEs, desktop, and browser.
That description is correct, but we could say it's only half the picture. It captures what the user sees, not the kind of system that has to sit underneath to make those actions safe to perform inside a real engineering environment. The distinction matters because agentic coding tools are entering workflows where mistakes are not limited to bad autocomplete suggestions. They can affect files, tests, build pipelines, tickets, cloud environments, and, increasingly, security-sensitive systems.
A recent academic paper, "Dive into Claude Code: The Design Space of Today's and Future AI Agent Systems," by Liu et al., offers a useful opportunity to look beyond the product's surface. The authors analyzed publicly available TypeScript source code from Claude Code v2.1.88 (following a leak of approximately 500,000 lines of proprietary code) and compared its architecture with that of OpenClaw, an open-source agent system built for a different deployment context. (At the time of writing this post, the Claude Code version was 2.1.140.)
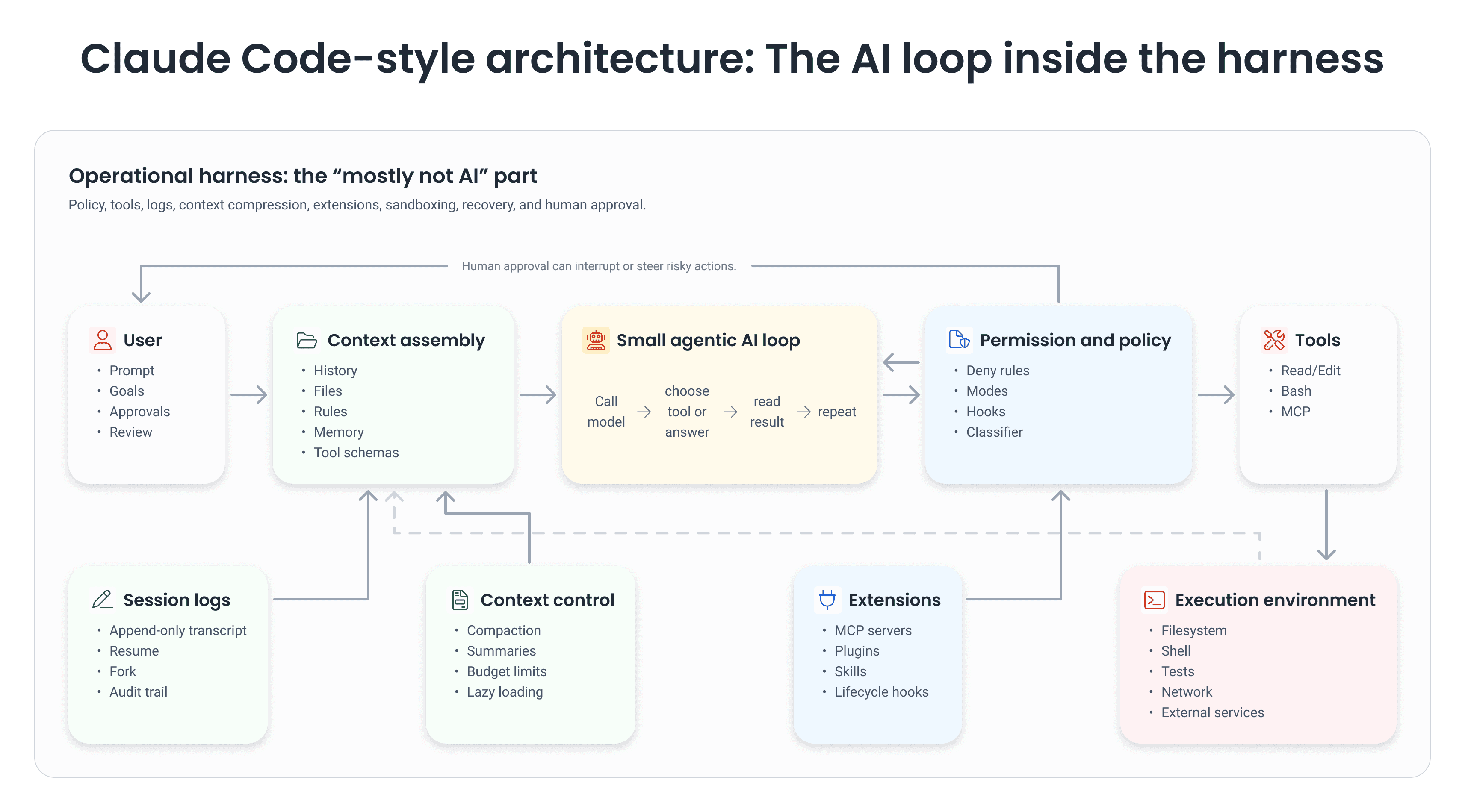
Their central observation fits on a single line: the core agent loop is small, but the surrounding harness is large. According to the abstract, the core is a while-loop that calls the model, runs tools, and repeats; most of the implementation, however, lives in the layers around that loop (permission systems, context management, extensibility, subagent orchestration, and session storage).
That finding has circulated online in a punchier, more viral form: "98% of Claude Code is not AI." The claim is directionally right, but phrased that way, it can be misleading. The article reports that a community analysis of the extracted source estimated that only about 1.6% of the codebase was AI decision logic, with the rest serving as operational infrastructure. That is not the same as saying the AI is unimportant. It means that the model's reasoning becomes useful only when surrounded by a carefully engineered system that decides what it can see, what it can touch, what it must ask before doing, how it recovers from errors, and how it keeps a long task coherent.
For security analysts, this is a reminder to review agent systems as software systems rather than as chatbots with file access. For software developers, it is a reminder that "AI coding" is still software engineering, with familiar concerns such as state, permissions, testing, observability, and rollback. For executives, it is a reminder that the strategic value of AI adoption will depend less on letting models act freely and more on building the operating conditions under which their actions remain useful, auditable, and safe.
What agentic coding tools are
The first AI-powered coding assistants mostly helped at the point of writing code. Autocomplete tools suggested lines or functions, and chat-based tools answered questions and generated snippets. Agentic coding tools go further. They do not merely suggest; they act. They can inspect a repository, search for relevant files, run a test suite, edit multiple files, read the results, adjust the plan, and keep going until they hit a plausible stopping point.
Claude Code's documentation describes this as an agentic loop with three overlapping phases: gather context, take action, and verify results. A bug fix may repeatedly cycle through all three. The model decides what to do based on what it learned from the previous step, while the user remains free to interrupt and steer. Broadly speaking, we can talk about a two-layer architecture: models that reason and tools that act, with Claude Code itself serving as the agentic harness that provides those tools, manages context, and runs the execution environment.
This division is key to understanding Liu et al.'s paper. Claude Code isn't a model floating freely through your machine. The model doesn't directly access the filesystem, run shell commands, or make network requests. Instead, it emits structured tool-use requests. The harness parses them, checks permissions, dispatches approved actions to tools, and feeds the results back into the next model call. The article highlights this separation as a security boundary: reasoning and enforcement live in different code paths, so what the model "wants" to do is not the same as what it has permission to do.
A useful analogy is not a robot with hands, but an expert sitting in a control room. The expert proposes actions. The control room contains displays, tools, checklists, locks, logs, and operators. The expert matters, but the control room determines what can happen.
A coding agent is not just a model. The model is a decision point inside a larger engineered harness that controls context, permissions, execution, recovery, and auditability.
The viral claim: mostly true, but easy to misread
The video that, in part, motivated me to write this post made several claims: that Claude Code's "AI part" is small; that the core is essentially a loop calling a model; that the rest consists of permissions, tools, context compression, and recovery systems; and that the winners in agentic AI will be differentiated by infrastructure rather than model choice alone.
Liu et al.'s paper largely supports that interpretation. It says the source-level analysis identified a simple core loop surrounded by subsystems for safety, extensibility, context management, delegation, and persistence. It also reports a permission system with seven modes and a machine-learning classifier, a five-layer context compaction pipeline, four extensibility mechanisms, and append-oriented session storage.
Still, "98% is not AI" can be misleading if you take it too literally. The model is still where task interpretation, code understanding, planning, and tool selection happen. Strip out the model, and the harness becomes a sophisticated shell of rules, schemas, and logs. Strip out the harness, and the model is a talkative consultant with no reliable way to act. The lesson Claude Code teaches isn't that the model is trivial; it's that the model's usefulness depends on the non-model architecture wrapped around it.
Furthermore, researchers cite an Anthropic internal survey of 132 engineers and researchers reporting that roughly 27% of Claude Code-assisted tasks were work that wouldn't have been attempted without the tool. That is, perhaps, the strongest argument against reading "98% is not AI" as "the model doesn't matter": the architecture enables qualitatively new workflows, not just faster versions of existing ones.
This wouldn't surprise anyone who has built production systems. A database isn't valuable because its query optimizer is brilliant; it's valuable because storage, indexing, transactions, permissions, backups, and observability all work together. A secure application is not secure because one authentication function does its job; it is secure because identity, authorization, validation, logging, monitoring, and recovery operate in concert. Agentic AI follows the same pattern.
The harness is where trust is negotiated
For security teams, the most interesting part of Claude Code may well be its permission system. According to Liu and colleagues, tool requests pass through a deny-first model: deny rules override ask rules, ask rules override allow rules, and unknown actions are escalated rather than silently permitted. The paper identifies up to seven permission modes: plan, default, accept edits, auto, don't ask, bypass permissions, and an internal bubble mode for subagent escalation.
The user-facing documentation presents a simpler version of the same idea. Claude Code lets users cycle through permission modes such as Default, Auto-accept edits, Plan mode, and Auto mode. It also lets users allow specific commands in settings, such as trusted test commands.
This matters because, in practice, humans aren't reliable permission-checking machines. The researchers cite Anthropic's own finding that users approved roughly 93% of permission prompts, which suggests these prompts often become rituals rather than meaningful reviews. A control that users almost always say yes to isn't really a control; it's closer to a speed bump. Anthropic's own engineering team estimates that sandboxing reduced the frequency of permission prompts by about 84%, which reframes the problem as human factors: the architectural response to unreliable approval is to reduce the number of decisions humans must make in the first place. Useful agent systems, therefore, need layered defenses: pre-filtered tools, rule evaluation, permission modes, classifiers, hooks, sandboxing, non-restoration of stale permissions, and session logs.
For security analysts, that broadens the review target well beyond "does the model refuse bad prompts?" It also has to cover where trust starts, which tools the model can see, whether deny rules behave deterministically, whether permissions survive session boundaries, whether shell commands run in a sandbox, whether hooks can modify tool inputs, and whether external connectors quietly widen the attack surface.
Context is a scarce resource
A second major lesson is context management. Claude Code can appear to "understand the whole codebase," and the documentation says it can work across files because it sees a user's project, terminal, Git state, CLAUDE.md instructions, auto memory, and configured extensions. But no model literally carries an entire engineering organization in its head. Every model call has a context window, and that window fills with instructions, file contents, command outputs, previous messages, tool schemas, memory, and summaries.
The paper explains that Claude Code's biggest challenge is managing its limited "memory space" or context. To avoid wasting this resource, the system uses several tricks: it loads project instructions only when absolutely necessary, hides technical details about tools until they are actually in use, asks subagents for short summaries rather than long reports, and sets "data budgets" for tool results. It also applies five context-reduction strategies before model calls, on the assumption that no single compaction method handles every kind of context pressure. Moreover, each layer operates with a different cost-benefit ratio, and the initial, less expensive layers run before the more expensive ones.
Meanwhile, Anthropic says something plainer: as context fills up, Claude Code clears older tool outputs first and summarizes the conversation if needed; persistent rules should be placed in CLAUDE.md rather than left in early conversation turns, because detailed instructions from earlier in a session may be lost. MCP tool definitions are deferred by default, and subagents have their own fresh contexts, so their work doesn't bloat the main conversation.
None of this is really a Claude Code novelty so much as a confirmation. As we mentioned in our previous post on software development in the agentic era, CLI agents already "treat context as a scarce resource," using targeted searches to find the files they need, reading only what's relevant, and managing the context window with precision. What the paper adds is a detailed look at what that discipline ends up looking like once it's wired into an actual production agent.
For developers, the practical takeaway is to stop treating a coding agent like an all-seeing colleague. Treat it instead like a colleague with a very large but still limited working memory. Put durable project rules in version-controlled files. Give it tests, examples, and constraints. Ask it to explore before implementing when the task is complex. Make verification part of the prompt. The model's answer will only ever be as good as the operational context the harness can assemble at the moment it's asked.
For executives, context management is also a cost and governance concern. Long-running AI work consumes tokens, tool calls, and human attention. If agents are expected to operate across large codebases, teams need conventions for what should enter persistent memory, what should belong in project instructions, what should be retrieved on demand, and what should never be exposed to the agent at all.
Tools do the work; the model chooses among them
Claude Code's model doesn't edit files with invisible hands. It uses tools. The article reports up to 54 built-in tools, with 19 always included and 35 included conditionally depending on feature flags, environment variables, and user type. Those built-in tools are then merged with MCP-provided tools, and the resulting action surface is filtered, deduplicated, and shaped before the model sees it.
That detail helps explain comments like those saying agents are merely another tool to throw into a project, and that every real solution to problems is still a comprehensive engineering solution. There is something right in that, although it undersells the model. AI agents are not just a tool in the same way grep is; they are flexible reasoning engines that can decide which tools to use, in what order, and based on what feedback. But they still need plain old software machinery underneath them to do anything reliably.
Claude Code's extensions illustrate the same point. Users can connect external services through MCP, store project instructions in CLAUDE.md, create skills for repeatable workflows, and use hooks to run commands before or after Claude Code actions. The product also supports subagents and custom agents for delegated work. Researchers map these mechanisms into a more architectural view: MCP servers add external tools, plugins package components, skills inject domain-specific instructions, and hooks intercept lifecycle events.
In other words, the "agent" is not a single thing. It is a composition of model calls, tool schemas, permission checks, files, command outputs, prompts, hooks, memories, summaries and logs. The model’s intelligence is real, but the product’s reliability comes from how those pieces are composed.
Why this matters for AppSec
For application security (AppSec), the most important shift is from detection to action. A tool that can only identify a vulnerability still leaves remediation, validation and deployment to humans. A coding agent could do more: inspect the vulnerable code path, write a patch, run tests, update dependencies, produce a pull request and document the reasoning. That makes it powerful, but also risky.
We've made a related point before. In our discussion of Claude Mythos, we argued that AI-driven vulnerability discovery doesn't end cybersecurity; it accelerates trends already underway, while leaving remediation as a complex, context-dependent challenge. Claude Code fits that broader picture. It can speed up remediation workflows, but only when its actions are constrained, reviewed, and verified.
Security teams should therefore evaluate agentic coding tools through several questions: Can the tool account for which files it read, which commands it ran, and why? Can it be restricted to read-only planning before making any change? Are dangerous commands denied by default? Are external services connected through MCP reviewed as part of the threat model? Are session logs available for audit? Can changes be reverted? Are generated fixes tested against exploit-relevant cases, not only against happy-path unit tests? Can the organization define policies centrally, instead of leaving each developer's local judgment to carry the weight?
Those questions are not anti-AI. They are the conditions under which AI assistance becomes useful in security work. In mature AppSec programs, the goal isn't to let agents "do security" on their own; it's to place them inside processes that already know how to handle evidence, risk, reproducibility, and accountability.
What should leaders take from the 98% figure?
The 98% figure is useful mainly because it shifts the conversation about where investment should go. If companies assume that agentic AI adoption is mainly a matter of buying access to the best model, they will underestimate the work required. The model is one component. The surrounding system is what determines whether the model can act in a way that's safe, measurable, and aligned with the organization's goals.
A serious adoption strategy, therefore, has to include engineering for the harness: permission policies, sandboxing, approved tool registries, context governance, secure MCP configurations, audit logs, rollback paths, CI integration, evaluation suites, and human review procedures. It also has to include training users not just to "prompt better," but to supervise better: to set constraints, provide verification targets, inspect diffs, understand failure modes, and know when not to delegate. This is, in many ways, the same shift we described in our previous post on agentic development: the engineer becoming an orchestrator who oversees multiple agents, defines high-level goals, resolves conflicts between them, and reviews the resulting pull requests, rather than a coder hunched over every line.
This is where another social media comment I saw becomes important. It said something like "Anyone shocked by this clearly didn't grasp the fundamentals of AI agents from the start." Comments like this one are harsh, but the underlying idea is reasonable. In the agent literature, the model has long been only one piece of a loop that includes planning, memory and tool use. What Claude Code makes visible is a remarkable production version of that idea. The glamorous part is the model response; the hard part is everything required before and after it.
The unresolved risk: people may learn less while doing more
Liu et al.'s paper isn't unreservedly enthusiastic. It raises a concern about long-term human capability. Claude Code may amplify short-term productivity, but the authors note that its architecture offers limited mechanisms that explicitly support long-term human improvement, deeper understanding, and sustained codebase coherence. They treat this as an evaluative lens rather than a core design value.
That concern shouldn't be brushed aside. If developers lean on agents to navigate codebases, make changes, and fix tests, they may ship faster while understanding less. If security analysts rely on agents to triage findings and propose fixes, they may process more alerts while losing the habit of deep manual investigation. And if executives measure only throughput, they may miss a slow decline in codebase coherence, review quality, or junior talent development.
The answer is not to reject agentic tools. It is to design workflows that preserve learning. Require agents to produce concise explanations of every change; ask for tests before fixes; use plan mode for complex work; have reviewers inspect not only whether tests pass, but also whether the agent respected architecture, threat models, and maintainability constraints; and treat agent output as a draft that has to earn trust through evidence.
A good coding agent should make professionals more capable, not just busier at a higher level of abstraction.
Conclusion: the future belongs to the harness
Claude Code is impressive, in part, because its model is powerful. But the deeper lesson of the referenced paper is that production agents succeed or fail depending on the infrastructure surrounding the model. The loop may be simple; the system is not.
For developers, the practical takeaway is to use agentic coding tools as collaborators inside an engineering workflow, not as autonomous substitutes. Security analysts have an architectural job to do: evaluate permissions, tools, context, memory, connectors, and logs, and not only the model's refusal behavior. And for executives, the question is strategic: the companies that get the most out of AI agents will be the ones that invest in the harness, the policies, and the verification culture around them.
The next phase of AI adoption will not be defined by a contest between humans and agents. It will be defined by how well organizations design the space where humans, models, and software systems work together. Claude Code's example was very valuable here because it shows how much engineering must be in place before an agent can act responsibly. In conclusion, useful AI agents are more engineering than magic.

Get started with Fluid Attacks' AI security solution right now
Other posts

























