Filosofía
De frágil a blindada: Nuestra nueva arquitectura de pruebas para el desarrollo de software


Staff Engineer
11 min
En Fluid Attacks llevamos casi 5 años construyendo y manteniendo nuestra plataforma. El camino hacia el desarrollo de una plataforma de clase mundial que permite tanto a los hackers como a los desarrolladores hacer software más seguro ha estado lleno de aprendizajes que no se podrían agrupar en una sola entrada de blog, ya que incluso dieron forma a la identidad y la filosofía del equipo de ingeniería de Fluid Attacks.
Dado que la calidad es una de nuestras principales preocupaciones, nos preguntamos constantemente: "¿Cómo podemos hacer que una aplicación que se despliega a producción más de 40 veces al día por un equipo de más de 20 desarrolladores se comporte como se espera y sea fácil de probar?"
Esta simple pregunta plantea una complejidad considerable y, por supuesto, más preguntas:
¿Podemos abordar las pruebas de una manera estándar para incrementar su mantenibilidad?
¿Qué tipos de pruebas deberíamos utilizar para nuestra aplicación?
¿Cómo podemos hacer que probar sea cómodo para los desarrolladores?
¿Podemos exigir a los desarrolladores mantener un determinado porcentaje de cobertura del código?
Los equipos pueden sentirse abrumados a medida que aparecen más preguntas; esto se debe a que las pruebas son una parte elemental de la creación y el mantenimiento de una aplicación, y las decisiones que se tomen en torno a ellas acabarán afectando a todo lo demás, incluyendo lo siguiente:
Si la aplicación hace o no lo que se supone que debe hacer.
El tiempo promedio de salida a producción, o cuánto tarda un desarrollador en llegar a producción.
La experiencia de desarrollo, o qué tan fácil es para los desarrolladores probar el comportamiento esperado en la aplicación.
Los costos y el tiempo de CI/CD, ya que los pipelines de la aplicación se componen en su mayoría de estas pruebas.
Si buscas inspiración para crear tu propio enfoque de pruebas o simplemente quieres ampliar tus conocimientos, quédate con nosotros. Hablaremos de nuestra plataforma, de las arquitecturas de pruebas que utilizábamos anteriormente —junto con sus puntos débiles—, de cómo evolucionamos hacia una arquitectura más rápida y fiable, y de las conclusiones que hemos sacado de este esfuerzo.
Dado que la complejidad técnica de esta publicación es de nivel intermedio-alto, recomendamos tener conocimientos básicos de lo siguiente:
Naturaleza básica de la plataforma de Fluid Attacks
Estas son las cosas más importantes a tener en cuenta sobre la plataforma de Fluid Attacks:
Es un servidor web monolítico escrito en Python.
Sirve a una API.
Utiliza AWS DynamoDB como base de datos principal.
Su código fuente se encuentra en el repositorio Universe de Fluid Attacks.
Arquitecturas de pruebas anteriores y sus puntos débiles
Pruebas unitarias
Este fue el primer enfoque de pruebas que utilizamos, el cual surgió debido a la necesidad básica de realizar pruebas, por lo que no pasó por una fase de diseño. A continuación mostramos un diagrama de alto nivel que lo describe:

Todas las pruebas utilizaban un archivo utils.py global para hacer mocking, que resultó ser muy complejo de mantener a medida que crecía. Además, las pruebas eran difíciles de comprender porque los mocks se producían en otro lugar.
Las pruebas existían en un directorio separado del código fuente de la aplicación. Mientras que este último se encontraba en
integrates/back/integrates, el código de pruebas se encontraba enintegrates/back/test/unit. Esto afectaba nuestra experiencia de desarrollo, ya que nos obligaba a cambiar constantemente entre dos directorios diferentes.Las pruebas se escribían utilizando pytest. Esto permitía a los desarrolladores escribir pruebas de muchas formas distintas, lo que afectaba la estandarización y aumentaba la carga cognitiva.
Todas las pruebas compartían una base de datos DynamoDB común que se ejecutaba en localhost y obtenía sus datos de un archivo database-design.json. Esto introducía flakiness, ya que a veces algunas pruebas cambiaban datos que otras utilizaban, provocando el fallo de estas últimas. Además, esta dependencia de localhost afectaba significativamente la velocidad de las pruebas debido a la lentitud de la inicialización de la base de datos.
El archivo database-design.json creció demasiado y se hizo difícil de mantener, ya que nadie sabía si datos específicos se utilizaban realmente en las pruebas.
El archivo database-design.json exigía a los desarrolladores describir entidades de base de datos enteras en lugar de solo los atributos que les interesaban en una prueba determinada, lo que hacía innecesariamente compleja la declaración de datos.
En un intento de mitigar el flakiness que se produce cuando todas las pruebas comparten una base de datos común, las pruebas se dividieron en dos categorías:
changes_db: Pruebas que leen y escriben en DynamoDB
not_changes_db: Pruebas que solo leen DynamoDB
Este enfoque conseguía hacer frente al flakiness hasta cierto punto, ya que al menos se separaban las pruebas que no modificaban la base de datos. Sin embargo, no solucionaba el problema de fondo: las pruebas compartiendo datos.
Los desarrolladores tenían que esperar a que terminara todo el conjunto de pruebas para conocer la cobertura del código. Esto era especialmente doloroso debido al hecho de que el pipeline de CI/CD fallaba si la cobertura era inferior a un umbral especificado, pero los desarrolladores solo podían validar esto después de ejecutar todo.
Las pruebas podían conectarse a Internet y comunicarse con servicios externos, lo que introducía más flakiness.
En resumen, estas pruebas eran:
Difíciles de entender y replicar debido a la excesiva libertad dada a los desarrolladores y a tener mocks y datos globales.
Lentas debido a la inicialización de la base de datos y a que obligaban a los desarrolladores a ejecutar todo el conjunto de pruebas para conocer la cobertura del código.
Flaky debido a los datos compartidos por las pruebas de forma global.
Por estas razones, la mayoría de los desarrolladores evitaron estas pruebas tanto como pudieron y, en su lugar, se centraron en los tipos que presentamos a continuación.
El código fuente de las pruebas unitarias puede encontrarse aquí.
Pruebas funcionales
La segunda arquitectura se construyó pensando en los principales problemas que encontramos en la anterior, pero enfocándonos en encontrar una forma de probar API endpoints. A continuación mostramos un diagrama de alto nivel que la describe:

Como había una prueba por API endpoint, rápidamente acabamos teniendo cientos de pruebas, lo que hizo que el pipeline de CI/CD creciera demasiado y los costos aumentaran.
Los mocks dejaron de ser globales, obligando a los desarrolladores a escribir mocks específicos para cada prueba. Esto mejoró la simplicidad y mantenibilidad de las pruebas.
Las pruebas existían en un directorio separado del código fuente de la aplicación. Mientras que este último se encontraba en
integrates/back/integrates, el código de prueba se encontraba enintegrates/back/test/functional. Esto afectaba nuestra experiencia de desarrollo, ya que nos obligaba a cambiar constantemente entre dos directorios distintos.Las pruebas se escribían utilizando pytest. Esto permitía a los desarrolladores escribir pruebas de muchas formas distintas, lo que afectaba a la estandarización y aumentaba la carga cognitiva.
DynamoDB pasó a ser local para cada prueba, significando la desaparición del flakiness causado por las pruebas que modificaban los datos utilizados por otras.
Aunque cada prueba tenía su propia base de datos durante el tiempo de ejecución, todas compartían datos genéricos en un archivo conftest.py. Esto provocaba flakiness, ya que una prueba podía adaptar los datos genéricos en función de sus necesidades específicas y, por tanto, romper otras pruebas.
Los datos genéricos seguían obligando a los desarrolladores a describir entidades de base de datos enteras en lugar de solo los atributos que les interesaban en una prueba determinada, lo que hacía que la declaración de datos fuera innecesariamente compleja.
Las pruebas seguían requiriendo que DynamoDB se ejecutara en localhost, lo que afectaba en gran medida la velocidad debido a la inicialización de la base de datos.
A medida que crecía el número de pruebas, el hecho de que cada una de ellas utilizara su propia DynamoDB en localhost aumentaba considerablemente la cantidad total de tiempo que dedicábamos a inicializar y poblar las bases de datos, lo que reducía significativamente la velocidad y aumentaba los costos del pipeline de CI/CD.
Como DynamoDB estaba vinculada a un puerto en localhost, solo podía funcionar una base de datos en un momento dado, lo que obligaba a los desarrolladores a ejecutar solo una prueba a la vez, lo que reducía enormemente la velocidad del equipo.
Las pruebas podían conectarse a Internet y comunicarse con servicios externos, lo que introducía más flakiness.
Los desarrolladores tenían que esperar a que terminara todo el conjunto de pruebas para conocer la cobertura. La situación empeoraba aún más porque las pruebas, que podían ser cientos, no podían ejecutarse simultáneamente. El impacto fue profundo, ya que conocer la cobertura localmente se hizo imposible (ejecutar cientos de pruebas de forma secuencial llevaba más de 10 horas).
En resumen, estas pruebas, en comparación con las pruebas unitarias, eran:
Más fáciles de entender, ya que cada prueba tenía mocks locales y se centraba en un API endpoint específico.
Menos flaky, ya que cada prueba tenía su propia base de datos.
Más lentas, ya que no podían ejecutarse simultáneamente.
Los desarrolladores seguían prefiriendo las pruebas funcionales a las unitarias debido a su simplicidad y a la reducción de flakiness.
El código fuente de las pruebas funcionales puede consultarse aquí.
Una nueva arquitectura de pruebas
Tras años de lucha con los dos diseños de pruebas anteriores, descubrimos varios puntos débiles comunes:
Las pruebas existían en un directorio separado del código fuente de la aplicación, lo que afectaba a la experiencia de los desarrolladores.
Las pruebas eran difíciles de comprender porque pytest otorgaba demasiada libertad a los desarrolladores.
Las pruebas eran flaky debido a las condiciones de carrera causadas por los datos de prueba compartidos y por tener acceso a Internet.
Proporcionar datos para una prueba determinada era demasiado complejo, ya que había que describir entidades completas de la base de datos, lo que incentivaba a los desarrolladores a copiar y pegar secciones enteras de datos en lugar de crear datos específicos para cada prueba.
Ambas arquitecturas eran muy lentas porque tenían que activar bases de datos.
Ambas arquitecturas requerían que los desarrolladores ejecutaran todas las pruebas antes de conocer la cobertura resultante.
Con estos puntos débiles en mente, nos centramos en implementar un nuevo enfoque que nos permitiera reemplazar las pruebas unitarias y funcionales. Después de dos meses de iteración, llegamos a una nueva arquitectura estándar que resolvía todos los problemas descritos anteriormente. A continuación mostramos un diagrama de alto nivel que la describe:
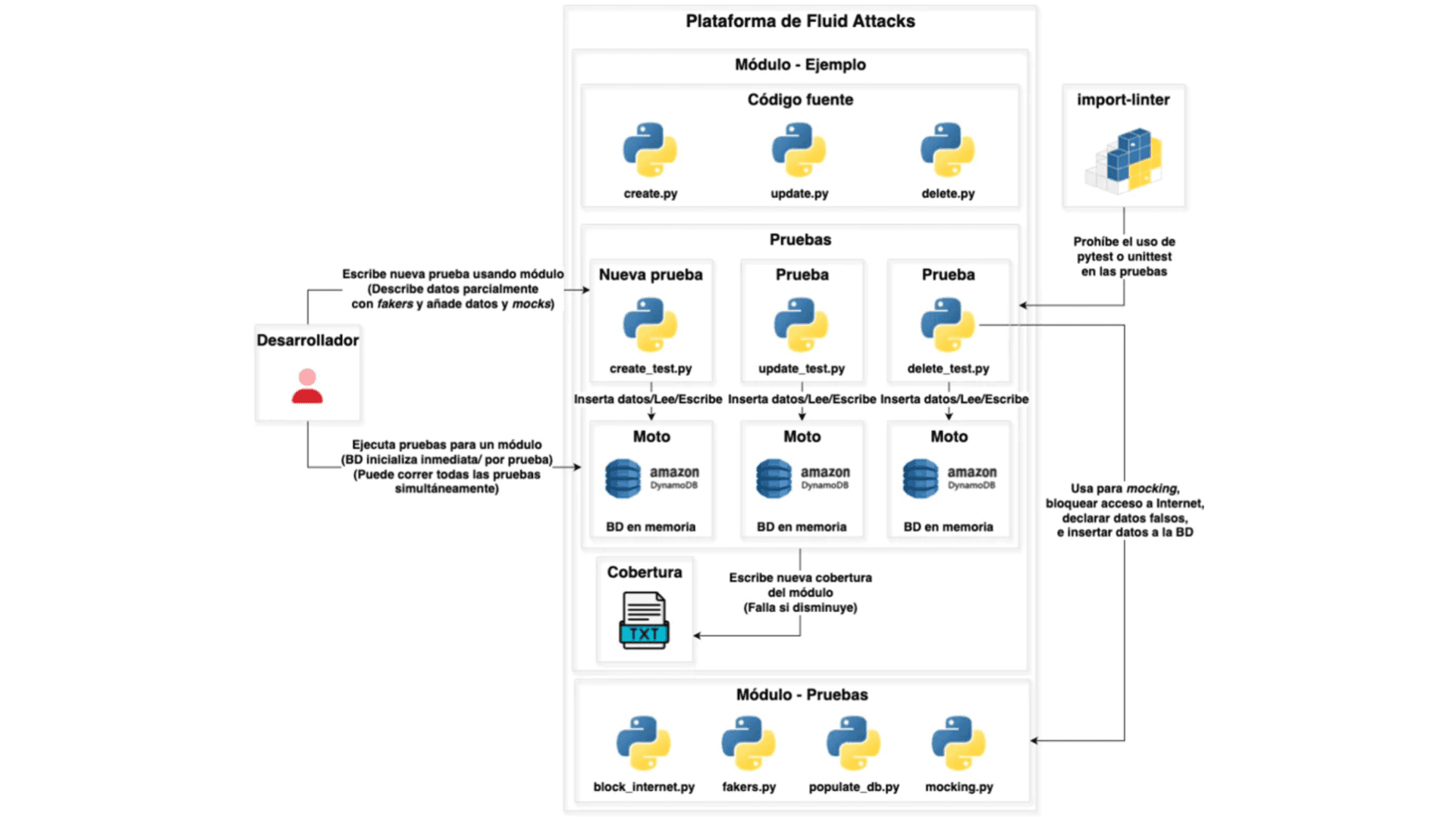
Las pruebas se encuentran en el mismo directorio que el código fuente de la aplicación, lo que mejora la experiencia de desarrollo al permitirnos encontrar fácilmente las pruebas para archivos o funciones específicos. Esto también permite a los desarrolladores adoptar mejores prácticas, como el desarrollo basado en pruebas (Test Driven Development, TDD).
Los desarrolladores pueden escribir pruebas para cualquier cosa, incluidas funciones específicas y API endpoints. Por lo tanto, podemos migrar todas las pruebas de arquitecturas anteriores a esta.
Implementa un módulo de pruebas que estandariza la forma de escribir pruebas, las cuales son considerablemente más fáciles de entender cuando se siguen patrones comunes.
El uso de import-linter prohíbe a los desarrolladores importar librerías como pytest y unittest, obligándolos a utilizar únicamente utilidades proporcionadas por el módulo de pruebas. Esto aumenta significativamente la estandarización de las pruebas.
Implementa fakers para que los desarrolladores puedan describir parcialmente las entidades de la base de datos, haciendo que la declaración de datos para cada prueba sea mucho más cómoda y mejorando la experiencia de los desarrolladores.
Las pruebas ya no pueden conectarse a Internet ni comunicarse con servicios externos, evitando flakiness.
Proporciona una forma estándar y declarativa para que los desarrolladores añadan datos a las pruebas, mejorando su experiencia.
Ofrece a los desarrolladores una forma de declarar fácilmente mocks dentro de las pruebas, lo que facilita su comprensión.
Implementa Moto, una librería que permite simular servicios de AWS como DynamoDB. Esto hace que las pruebas se ejecuten a gran velocidad al instanciar una base de datos de DynamoDB en memoria dentro del contexto de Python de cada prueba.
Como las bases de datos existen en el contexto de Python, ya no están vinculadas a un puerto en localhost, lo que permite a los desarrolladores ejecutar pruebas simultáneamente, aumentando aún más la velocidad.
Introduce un archivo de cobertura para cada módulo de la aplicación, lo que permite a los desarrolladores ejecutar simultáneamente todas las pruebas de un módulo determinado y conocer al instante los resultados de la cobertura del código, mejorando enormemente la experiencia y la velocidad de desarrollo.
Disminuye el tamaño del pipeline de CI/CD al pasar de un enfoque de un-job-por-prueba a uno de un-job-por-módulo, lo que reduce considerablemente los costos de CI/CD.
En resumen, en comparación con las anteriores, la nueva arquitectura de pruebas es:
Más cercana al código fuente de la aplicación, lo que mejora la experiencia de los desarrolladores.
Estándar, ya que los desarrolladores deben utilizar el módulo de pruebas especialmente diseñado para nuestras necesidades.
Flexible, ya que permite a los desarrolladores probar cualquier cosa dentro de la aplicación.
Rápida, ya que utiliza Moto para las bases de datos y las pruebas pueden ejecutarse de forma simultánea.
Menos flaky, ya que cada prueba utiliza sus propios datos y mocks y no puede conectarse a Internet.
Escalable, ya que el número de jobs de CI/CD es igual al número de módulos de la aplicación.
El código fuente de estas pruebas puede verse aquí (nótese que se trata del directorio de código fuente de la aplicación, como se ha mencionado anteriormente).
Puede encontrarse más información técnica sobre la nueva arquitectura aquí.
Conclusiones
Haz que tus pruebas coexistan con el código de la aplicación, ya que esto permite a los desarrolladores adoptar buenas prácticas como TDD y mejora la navegación.
Si estás construyendo una gran aplicación que necesitará cientos de pruebas, en lugar de utilizar directamente librerías de pruebas de propósito general como pytest o unittest, céntrate en crear tu propio enfoque de pruebas que reutilice funcionalidades críticas de esas librerías (p. ej., un wrapper o un módulo de pruebas). Luego, utiliza import-linter para exigir a los desarrolladores emplear ese enfoque. Esto garantizará la coherencia de tus pruebas y ayudará considerablemente a los desarrolladores a mantenerlas en el largo plazo.
Usa librerías que simulen servicios core, como Moto, en lugar de servir esos componentes en localhost para que así las pruebas se ejecuten mucho más rápido.
Evita los estados globales para tus pruebas tanto como sea posible (datos, mocks, etc.), ya que introducen flakiness. Utiliza librerías como Moto para proporcionar un estado local para cada prueba.
Prohíbe que tus pruebas lleguen a Internet para así evitar flakiness.
Si estás aplicando políticas estrictas para la cobertura del código, asegúrate de que los desarrolladores puedan validarlo localmente con la mayor comodidad posible.
Lo que está por venir
Hay varias cosas que haremos en el futuro en relación con nuestra nueva arquitectura de pruebas:
Migrar todas las pruebas de nuestras arquitecturas previas a esta con el fin de dejar obsoletos los flujos antiguos y mantener las cosas simples. Puedes encontrar más información al respecto aquí.
Hacer que esta arquitectura soporte otros componentes críticos para el monolito, tales como AWS S3, AWS OpenSearch y AWS lambda. De esta forma, los desarrolladores podrán simular fácilmente otras partes del monolito manteniendo todos los beneficios de la arquitectura actual. Más detalles aquí.
Esta arquitectura se hizo específicamente para el monolito de la plataforma de Fluid Attacks, por lo que está acoplada a él, lo que nos impide utilizarla en otras aplicaciones que podrían beneficiarse de algunas de sus propiedades. Una de las cosas que pensamos hacer a largo plazo es desacoplar el modelo de datos de Fluid Attacks del monolito para que otras aplicaciones también puedan utilizarlo. El primer paso que daremos en esa dirección se describe aquí.
Agradecimientos especiales
Por último, quiero dar mi más sincero agradecimiento a todos los que han creído en este proyecto:
Juan Restrepo, por animar al equipo a descubrir nuevas y mejores formas de hacer las cosas.
Daniel Betancur y Juan Echeverri, por estar siempre ahí cuando necesitábamos algo para seguir avanzando.
Juan Diaz, por implementar partes centrales de la nueva arquitectura como CLI, fakers, Moto, etc.
Brandon Lotero, por implementar los tipos de base de datos.
David Acevedo, por implementar las reglas de import-linter y el bloqueo de Internet.
Felipe Ruiz, por todo el apoyo en la edición, traducción y publicación de esta entrada del blog.
El equipo de ingeniería de Fluid Attacks, por su apoyo y retroalimentación.

Empieza ya con la solución de ASPM de Fluid Attacks
Suscríbete a nuestro boletín
Mantente al día sobre nuestros próximos eventos y los últimos blog posts, advisories y otros recursos interesantes.
Otros posts
























