Opiniões
GPT-5.4-Cyber, GPT-5.5, and the next phase of AI-powered cybersecurity


Redator e editor de conteúdo
11 min
In early April 2026, Anthropic put the cybersecurity industry on edge with Claude Mythos Preview and Project Glasswing, a model and partner program we covered in depth in our earlier post on Mythos and the future of AppSec. About a week later, OpenAI—so to speak—answered with GPT-5.4-Cyber and an expanded Trusted Access for Cyber (TAC) program, and on April 23, it released GPT-5.5, a broader frontier model the company describes as stronger than GPT-5.4 in coding, tool use, autonomy, and cybersecurity.
Mythos was presented as a model so capable at finding and exploiting vulnerabilities that Anthropic decided not to release it broadly, at least for now. OpenAI's GPT-5.4-Cyber was framed differently: as a cyber-permissive version of GPT-5.4, fine-tuned for defensive work and made available through tiered identity verification. GPT-5.5, in turn, was not branded as a cyber-only model, yet OpenAI still dedicated part of its release to cybersecurity and classified the model as "High" capability in that domain under its Preparedness Framework.
The result is a useful comparison, although not a simple one. Mythos, GPT-5.4-Cyber, and GPT-5.5 could be seen—mainly the first two—as three different answers to the same question: how should frontier AI be deployed once it becomes meaningfully useful for both defending and attacking software?
What OpenAI actually released with GPT-5.4-Cyber
GPT-5.4-Cyber is not a separate frontier model. It is a version of GPT-5.4 trained for defensive cybersecurity workflows, and the most important change is not that the model "knows security"; it is that the refusal boundary has been deliberately lowered for legitimate security work. Verified defenders should encounter less friction when asking for help with vulnerability research, defensive programming, malware analysis, reverse engineering, and other dual-use tasks that general-purpose models often refuse to engage in.
The headline capability is binary reverse engineering. According to OpenAI, GPT-5.4-Cyber can support workflows where security professionals analyze compiled software for malware potential, vulnerabilities, and security robustness without needing the original source code. That matters because binary analysis has traditionally required scarce expertise and weeks of manual labor; a model that can help a defender triage executables, reason about suspicious behavior, and map likely attack surfaces could materially change the economics of malware analysis and vulnerability research, provided the results are validated carefully.
Access is limited to higher tiers of OpenAI's TAC program, which relies on identity verification, enterprise trust signals, and additional authentication for users seeking more permissive capabilities. Individual defenders can verify their identity through a dedicated portal, which gives them reduced friction around safeguards for existing models. Enterprise teams can request access through their OpenAI representative for the entire security organization. Users seeking the most permissive capabilities, including GPT-5.4-Cyber itself, must complete additional authentication and may be required to waive Zero-Data Retention so that OpenAI can monitor how the model is being used, particularly when it is reached through third-party platforms.
OpenAI's stated principles are democratized access, iterative deployment and ecosystem resilience: rather than have a small committee decide who is "trusted enough" to defend their systems, the company wants to put increasingly capable tools in the hands of verified defenders while learning from real use, while hardening safeguards against jailbreaks and adversarial misuse, and supporting the wider security ecosystem through grants, open-source initiatives and products such as Codex Security. OpenAI says Codex Security has contributed to more than 3,000 critical and high-severity fixed vulnerabilities, and that its Codex for Open Source program has reached more than 1,000 open-source projects with free security scanning.
One important caveat is that OpenAI has not published a detailed public benchmark card for GPT-5.4-Cyber itself. The public record is currently stronger on what the model is intended to do, how access is governed, and how it fits into OpenAI's broader cyber strategy than on how it performs across independent vulnerability discovery tasks. That does not make the model insignificant, but it does mean that head-to-head comparisons with Mythos should be read with caution.
GPT-5.5: not "GPT-5.5-Cyber," but still highly relevant
GPT-5.5 arrived nine days after the GPT-5.4-Cyber announcement, presented as a general frontier model for complex work across coding, research, data analysis, document creation, spreadsheets, and computer use. OpenAI emphasizes that GPT-5.5 can understand a messy, multi-step task earlier, use tools more effectively, check its own work, and continue through ambiguity with less micromanagement. For cybersecurity, that combination matters because real security work is rarely a single prompt; it is a sequence of reading code, forming hypotheses, running tools, interpreting failures, proposing fixes, and verifying that the risk has actually changed.
The release also highlights coding improvements in Codex, including stronger performance on long-context engineering tasks, as well as debugging, testing, and validation. Early testers reportedly described a better ability to understand the shape of a system, identify where a fix belongs, and anticipate how other parts of the codebase might be affected. That is directly relevant to application security, because many remediation failures happen not at the moment a bug is found but when the fix is incomplete, breaks surrounding logic, ignores a related sink or source, or fails to address the root cause. A model that can hold more context across a broader codebase can be more valuable as a remediation assistant than as a detector alone.
Benchmarks and the limits of comparison
OpenAI's published evaluation table places GPT-5.5 at 81.8% on CyberGym, compared with 79.0% for GPT-5.4 and 73.1% for Claude Opus 4.7. CyberGym includes 1,507 historical vulnerabilities across 188 software projects and primarily tests whether agents can generate proof-of-concept tests that reproduce vulnerabilities from descriptions and codebases. The benchmark's authors emphasize that this is difficult because agents must reason across full repositories, locate relevant code, and produce working reproduction artifacts. Anthropic's own materials, separately, claim Claude Mythos Preview reaches 83.1% on similar reproduction tasks.
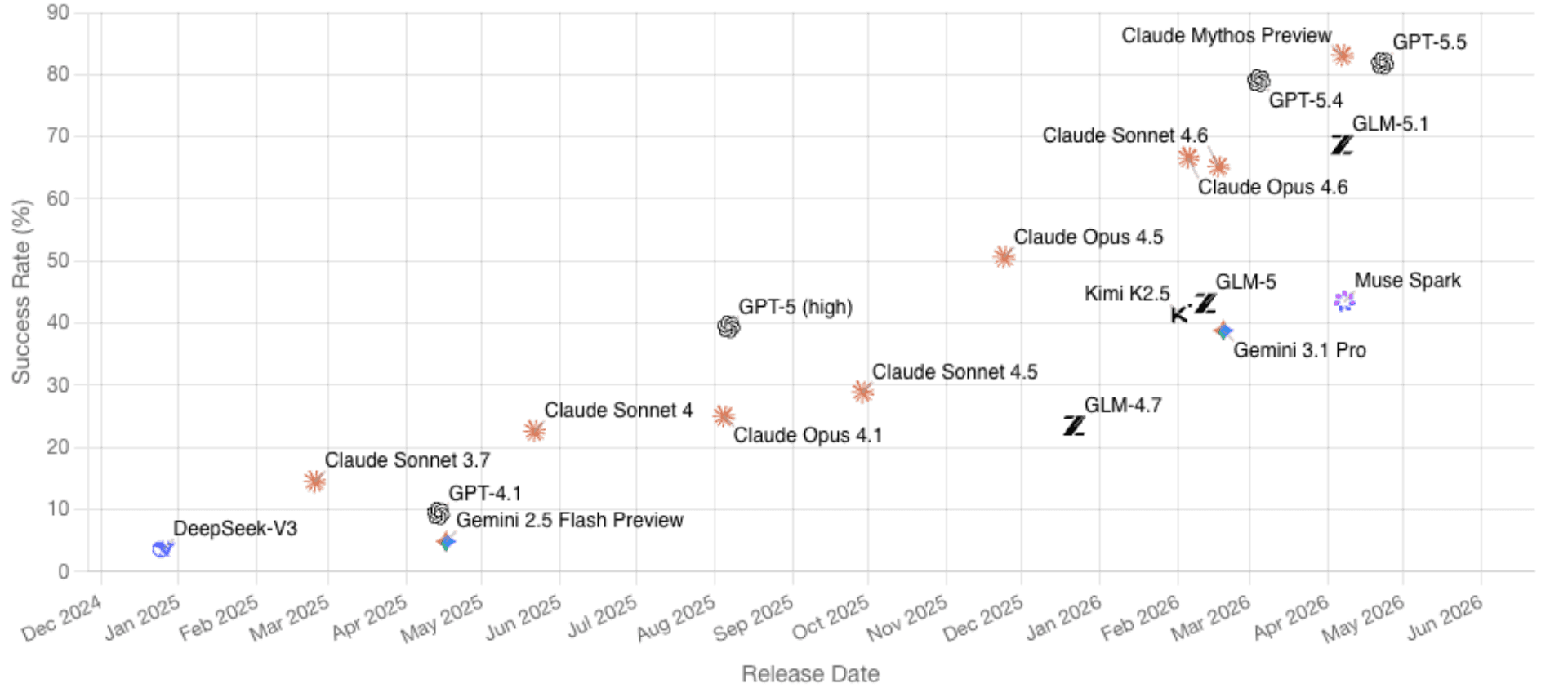
GyberGym benchmark (image taken from cybergym.io on April 30, 2026)
These numbers should not be overread. The table compares GPT-5.5 with GPT-5.4, not with GPT-5.4-Cyber, so the cyber-permissive variant's true position remains unclear. CyberGym is also a vulnerability reproduction benchmark, not a full simulation of offensive operations against hardened enterprise targets with live defenders, endpoint detection, identity controls, and incident response. Production behavior may differ further, since OpenAI's evaluations were run with high reasoning effort in a research environment.
The picture becomes more vivid in longer, multi-step evaluations that simulate full attack chains. The UK AI Security Institute (UK AISI), for instance, tested Mythos on a 32-step scenario known as the TLO scenario, where the model completed the entire attack chain from start to finish in three out of ten attempts and averaged 22 of the 32 steps across all tries. No AI model evaluated before had been able to complete that specific challenge end-to-end.
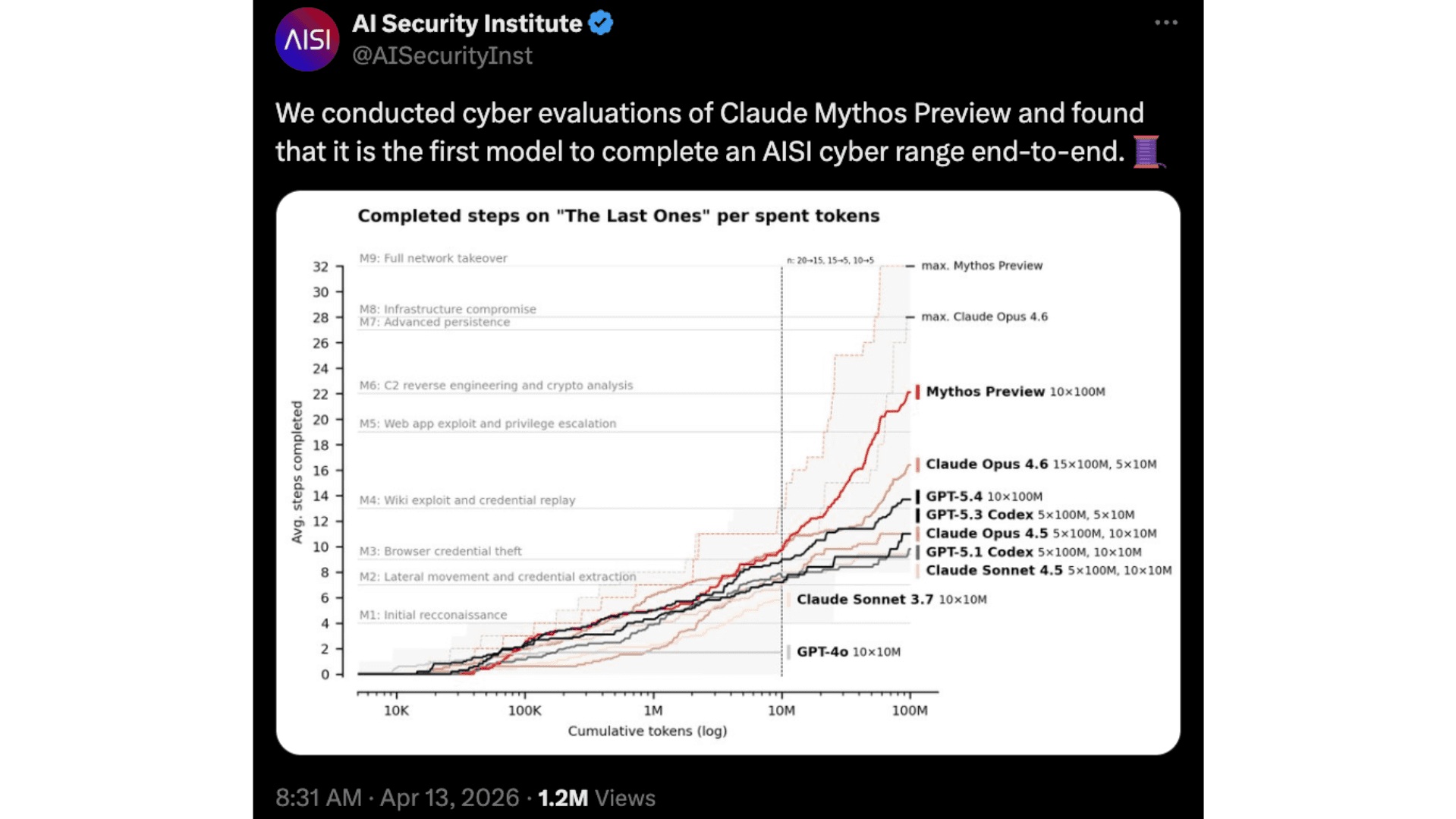
UK AI Security Institute X post on the Mythos TLO scenario evaluation
GPT-5.5 was put through similar long-horizon evaluations. OpenAI's system card reports a 93.33% combined pass rate on certain cyber range scenarios, compared with 73.33% for GPT-5.4 Thinking, attributing the higher pass rate to persistence at exploitation. External evaluators reinforced the picture: Irregular reported that GPT-5.5 could provide significant assistance to novice or moderately skilled operators and could help highly skilled operators in some cases, while UK AISI judged GPT-5.5 the strongest overall model it had tested on narrow cyber tasks, though within the margin of error, and found that the model solved one 32-step corporate-network cyber range end-to-end in one out of ten attempts.
High capability, but below critical
Under OpenAI's Preparedness Framework, both GPT-5.4-Cyber and GPT-5.5 are classified as having a "High" cybersecurity capability, while remaining below the "Critical" threshold. A High-capability model can automate end-to-end cyber operations against reasonably hardened targets or significantly remove bottlenecks in discovering operationally relevant vulnerabilities. A Critical-capability model would be able to identify and develop functional zero-day exploits across many hardened real-world critical systems without human intervention, or execute novel end-to-end cyberattack strategies against hardened targets given only a high-level goal.
OpenAI says GPT-5.5 was tested against widely deployed, hardened software projects using high test-time compute and verifier oracles, and that it did not produce functional critical-severity exploits in the standard configurations tested. The company has indicated that if a future model were to reach the Critical threshold, additional development would be paused until stronger safeguards could be implemented. (What about Mythos? Stay tuned.)
OpenAI's safety response for GPT-5.5 is also stricter than for earlier general models, with tighter controls around higher-risk activity, sensitive cyber requests, and repeated misuse, while trusted access is used to reduce unnecessary refusals for verified defenders. In practice, OpenAI is splitting the experience: broad access to GPT-5.5 comes with stronger classifiers and monitoring; trusted cyber users can request fewer restrictions for legitimate defensive work.
Comparison with Claude Mythos and Project Glasswing
Anthropic's framing is more dramatic. As we expressed in our previous blog post (which we invite you to read for more details), the company describes Claude Mythos Preview as a general-purpose language model that is especially capable at computer security tasks, and says Mythos can identify and exploit zero-day vulnerabilities in every major operating system and web browser when directed to do so. Mythos, supposedly, can also reverse-engineer exploits on closed-source software and turn known-but-not-yet-widely-patched vulnerabilities into working exploits, with a reported success rate above 72% on certain exploit-generation tasks.
Project Glasswing is Anthropic's response to the deployment problem. Rather than making Mythos broadly available, Anthropic is giving selected partners, including Google, Microsoft, and NVIDIA, access to identify and fix vulnerabilities in foundational systems that account for a large portion of the shared attack surface. The work spans local vulnerability detection, black-box testing of binaries, endpoint security, and penetration testing. Anthropic committed $100 million in model usage credits to Glasswing and related participants, along with donations to open-source security organizations, and committed to publicly reporting what it learned within 90 days, where disclosure permits.
The contrast with OpenAI is therefore partly technical and partly political. Mythos is presented as a breakthrough frontier model whose autonomous cyber capability requires a very narrow release. GPT-5.4-Cyber is presented as a specialized, cyber-permissive variant of an existing model, placed behind a broader verification system. GPT-5.5 is a general model whose cyber capabilities are strong enough to require enhanced safeguards, but, according to OpenAI, it remains below the Critical threshold. These differences matter because public commentary often treats GPT-5.4-Cyber and Mythos as direct equivalents. The two are similar in being gated, dual-use, and defense-oriented; they differ in their stated capability profiles, evidence bases, and access philosophies.
Anthropic has published more explicit examples of zero-day discovery and exploit generation, while OpenAI has published more details about its access framework and general cyber evaluations. On benchmarks, Anthropic says Mythos substantially outperforms Opus 4.6, and OpenAI reports GPT-5.5 outperforming GPT-5.4 and Opus 4.7 on CyberGym, but Opus 4.7 is not Mythos, and GPT-5.4 is not necessarily GPT-5.4-Cyber. Any clean league table would be misleading unless the same tasks, tool environments, refusal settings, and verification standards were used.
The two access models also encode different bets. Anthropic's bet is that certain capabilities should be kept within a tight consortium until safeguards improve; OpenAI's is that the defender population needs broader, verified access because attackers will not wait. A narrow release reduces distribution risk but can create a two-tier security ecosystem in which only the largest organizations receive the strongest tools; a broader trusted-access model helps more defenders but requires robust identity verification, monitoring, abuse response, and ongoing governance. The harder question is not which company sounds more responsible; it is whether either approach can scale without creating blind spots, dependencies, or accidental advantage for attackers.
Trust under stress: the Mythos vendor incident
The governance question became sharper after Bloomberg reported that unauthorized users had accessed Mythos through a third-party vendor environment, with the access reportedly coinciding with the day Anthropic first announced its limited testing plans. Anthropic confirmed that it was investigating the report. The incident, considered together with earlier issues such as flaws in the Model Context Protocol (MCP) and a separate human-error leak that exposed roughly 500,000 lines of Claude Code source-map material on npm, illustrates a central challenge for every lab building cyber-capable AI: access control, vendor security, and operational monitoring become part of the safety case, not merely administrative details.
Market dynamics: revenue, "criti-hype" and the financial sector
The competition between Anthropic and OpenAI is not only technical; it is also a contest for market dominance and investor confidence. Anthropic, reportedly preparing for an initial public offering, has seen its annualized revenue reach $30 billion, surpassing OpenAI's most recently reported figure. Some industry observers have labeled the strategy of describing a model as "too dangerous to release" as "criti-hype," arguing that warning loudly about a technology's extreme dangers can simultaneously inflate its perceived value to investors. Whether or not one accepts that framing, it explains why every Mythos disclosure functions as both a safety message and a brand statement.
OpenAI has leaned in a different direction by anchoring its cyber program in enterprise partnerships. Major financial institutions, including Bank of America, BlackRock, BNY, Citi, Goldman Sachs, JPMorgan Chase, and Morgan Stanley, have signed on to support or participate in the Trusted Access for Cyber program. These institutions manage sprawling legacy systems that are difficult to replace and expensive to secure, making them natural early adopters of AI-assisted defense at scale.
The action gap among companies
Perhaps the most important realization of 2026 is that vulnerability detection itself is on its way to becoming a common good; it is increasingly cheap, abundant, and automated. As Rafael Álvarez, Co-founder of Fluid Attacks, has argued, the primary problem in application security is rarely discovery; it is discipline. Companies often know exactly what is broken yet fail to fix it due to resource constraints, poor prioritization, or a lack of context.
The flood of AI-generated vulnerability reports adds new pressure on software maintainers. Even a high-quality finding requires human time to validate, test, and merge, and the capacity of open-source projects to absorb a large volume of findings does not scale at the same rate as the AI's ability to surface them. The window between disclosure and exploitation continues to narrow, rendering traditional patching schedules obsolete when an adversary can move from discovery to exploitation in minutes.
The role of the security engineer is changing in response. Engineers are no longer the primary "finders" of vulnerabilities; they are becoming the deciders who orchestrate AI agents, validate their results, and make high-stakes calls on risk prioritization. The most valuable security platforms in this environment will be those that can translate findings into actionable decisions, coordinate remediation at scale across complex environments, provide continuous verification that a fix actually reduced exposure, and integrate cleanly into real development and production workflows.
What defenders should take from these releases
The UK National Cyber Security Centre has argued that frontier AI is already changing the cost, speed, and scale of cyber operations for both attackers and defenders, including tasks such as exploit-code writing, system-architecture understanding, and tool use. NCSC also argues that defenders retain structural advantages if they prepare properly, because they control their own systems, logs, build pipelines, identity architecture, and remediation processes. That advantage disappears when organizations treat AI as a scanner bolted onto an already fragmented security workflow.
For application security programs, the practical lesson is to build a closed loop around AI-assisted findings. A useful workflow connects discovery, evidence, business context, exploitability, ownership, remediation guidance, retesting, and auditability. It normalizes findings from multiple sources rather than creating another silo, and it preserves room for human review where the cost of being confidently wrong is high. It also tracks model performance in security-specific terms: false positives, false negatives, reproducibility, fix quality, time-to-validate, time-to-remediate, regression rate, and integration with existing developer workflows.
The operational question for a CISO is therefore not only whether GPT-5.5 scores higher than GPT-5.4 on CyberGym, or whether Mythos is stronger at zero-day discovery, but whether a security team can use these systems without overwhelming maintainers, flooding CVE processes, pushing unsafe patches, or granting excessive trust to unverified AI outputs. A model that accelerates discovery without strengthening remediation discipline simply creates a larger backlog with more impressive language around it.
The same logic applies in critical infrastructure, financial services, healthcare, telecom, and operational technology, where legacy code, brittle dependencies, and long maintenance windows already constrain how quickly fixes can ship; if AI keeps making discovery cheaper while patching remains constrained, the gap between known risk and resolved risk becomes a central measure of organizational resilience.
Strategic recommendations for leadership
For executives and security leaders trying to translate these announcements into action, a few priorities stand out:
Adopt tiered access early. Security teams should begin the Trusted Access for Cyber application process now, so that they have verified access to models like GPT-5.4-Cyber when needed, rather than scrambling during a crisis.
Use AI as a triage assistant, not as an oracle. Apply the strongest models to specific, narrow use cases such as binary reverse engineering for malware analysis, or policy-constrained code review inside CI/CD pipelines, where outputs can be verified against deterministic checks.
Invest in the remediation loop, not only in detection. Establish a closed-loop system in which ownership is assigned, remediation is tracked, fixes are rigorously re-tested, and risk exposure reduction is measurable.
Plan for audit and oversight. As automated findings become more prevalent, regulatory regimes such as the EU AI Act will require documented human oversight of how these systems are used inside the security function.
The value shifts from finding to deciding
GPT-5.4-Cyber and GPT-5.5 show that OpenAI is moving toward a layered cyber strategy: more capable general models, stronger safeguards for broad access, and more permissive workflows for verified defenders. Claude Mythos shows that Anthropic is willing to present frontier cyber capabilities as too powerful for a normal release while channeling them through a controlled partner program. These strategies differ in important ways, yet they point toward the same market structure: the strongest AI capabilities will increasingly be distributed through trust tiers, security requirements, and monitored access, rather than through simple public availability.
For security providers and enterprise teams, the differentiator will shift accordingly. Detection will remain important, yet it will lose strategic value if it is not paired with validation, prioritization, and verified remediation. The most valuable security programs will be those that can turn abundant machine-generated findings into reliable decisions: which issues matter, who owns them, how they should be fixed, whether the fix is safe, and whether the underlying risk is actually gone. AI agents can assist across that chain, but they do not remove the need for accountability, evidence, and human judgment.
The question for organizations is therefore not whether to wait for the perfect model, but whether they are preparing the operating approach required to use any of these systems responsibly. That means inventorying software and dependencies, reducing unresolved vulnerability debt, improving ownership and remediation SLAs, validating AI outputs with deterministic tools and expert review, and maintaining evidence that fixes reduce exposure.
Security value is not measured by the number of findings generated; it is measured by the amount of risk reduced. As frontier AI accelerates discovery and makes it more widely available, the organizations that come out ahead will be those that can absorb the pace without losing control.
If you think your company needs help implementing strategies to address these transformations in cybersecurity with AI, don't hesitate to contact Fluid Attacks.

Get started with Fluid Attacks' ASPM solution right now
Assine nossa newsletter
Mantenha-se atualizado sobre nossos próximos eventos e os últimos posts do blog, advisories e outros recursos interessantes.
Outros posts