Opiniones
GPT-5.4-Cyber, GPT-5.5 y la siguiente fase de la ciberseguridad impulsada por IA


Escritor y editor
13 min
A principios de abril de 2026, Anthropic puso en alerta al sector de la ciberseguridad con Claude Mythos Preview y Project Glasswing, un modelo y un programa de socios que cubrimos en detalle en nuestra publicación anterior sobre Mythos y el futuro de AppSec. Aproximadamente una semana después, OpenAI —por así decirlo— respondió con GPT-5.4-Cyber y una ampliación de su programa Trusted Access for Cyber (TAC), y el 23 de abril lanzó GPT-5.5, un modelo de frontera más amplio que la compañía describe como superior a GPT-5.4 en programación, uso de herramientas, autonomía y ciberseguridad.
Mythos fue presentado como un modelo tan capaz de encontrar y explotar vulnerabilidades que Anthropic decidió no lanzarlo ampliamente, al menos por ahora. GPT-5.4-Cyber de OpenAI se planteó de forma distinta: como una versión ciberpermisiva de GPT-5.4, ajustada para el trabajo defensivo y disponible mediante verificación de identidad por niveles. GPT-5.5, a su vez, no se presentó como un modelo exclusivo para ciberseguridad; aun así, OpenAI dedicó parte de su lanzamiento a la ciberseguridad y clasificó al modelo con capacidad "Alta" en ese dominio dentro de su Preparedness Framework.
El resultado es una comparación útil, aunque no sencilla. Mythos, GPT-5.4-Cyber y GPT-5.5 podrían verse —sobre todo los dos primeros— como tres respuestas distintas a la misma pregunta: ¿cómo debería desplegarse la IA de frontera una vez que empieza a ser significativamente útil tanto para defender como para atacar software?
Lo que OpenAI realmente lanzó con GPT-5.4-Cyber
GPT-5.4-Cyber no es un modelo frontera aparte. Es una versión de GPT-5.4 entrenada para flujos de trabajo defensivos de ciberseguridad, y el cambio más importante no es que el modelo "sepa de seguridad"; es que el umbral de rechazo se redujo deliberadamente para el trabajo legítimo de seguridad. Los defensores verificados deberían encontrar menos fricción al solicitar ayuda para investigación de vulnerabilidades, programación defensiva, análisis de malware, ingeniería inversa y otras tareas de doble uso que los modelos de propósito general suelen rechazar.
La capacidad más destacada es la ingeniería inversa binaria. Según OpenAI, GPT-5.4-Cyber puede apoyar flujos de trabajo en los que los profesionales de seguridad analizan software compilado para evaluar su potencial de malware, sus vulnerabilidades y su solidez de seguridad sin necesidad del código fuente original. Eso importa porque, tradicionalmente, el análisis binario ha requerido experiencia que es escasa y semanas de trabajo manual; un modelo que pueda ayudar a un defensor a clasificar ejecutables, razonar sobre comportamientos sospechosos y mapear superficies de ataque probables podría cambiar de forma material la economía del análisis de malware y la investigación de vulnerabilidades, siempre que los resultados se validen con cuidado.
El acceso está limitado a los niveles superiores del programa TAC de OpenAI, que se basa en verificación de identidad, señales de confianza empresarial y autenticación adicional para los usuarios que buscan capacidades más permisivas. Los defensores individuales pueden verificar su identidad a través de un portal dedicado, lo que les reduce la fricción con las salvaguardas de los modelos existentes. Los equipos empresariales pueden solicitar acceso a través de su representante de OpenAI para toda la organización de seguridad. Los usuarios que buscan las capacidades más permisivas, incluido el propio GPT-5.4-Cyber, deben completar una autenticación adicional y puede que se les pida renunciar a la Zero-Data Retention para que OpenAI pueda supervisar cómo se está usando el modelo, especialmente cuando se accede a él a través de plataformas de terceros.
Los principios declarados por OpenAI son el acceso democratizado, el despliegue iterativo y la resiliencia del ecosistema: en lugar de que un pequeño comité decida quién es "lo suficientemente confiable" para defender sus sistemas, la compañía quiere poner herramientas cada vez más capaces en manos de defensores verificados mientras aprende del uso real, refuerza las salvaguardas contra jailbreaks y el uso adversarial, y apoya al ecosistema de seguridad más amplio mediante subvenciones, iniciativas de código abierto y productos como Codex Security. OpenAI afirma que Codex Security ha contribuido a más de 3.000 vulnerabilidades de severidades crítica y alta corregidas, y que su programa Codex for Open Source ha llegado a más de 1.000 proyectos de código abierto con análisis de seguridad gratuitos.
Una salvedad importante es que OpenAI no ha publicado una tarjeta de evaluación pública detallada para GPT-5.4-Cyber en sí. El registro público es actualmente más sólido en cuanto a lo que el modelo pretende hacer, cómo se gobierna el acceso y cómo encaja en la estrategia cibernética más amplia de OpenAI, que en cuanto a cómo rinde en tareas independientes de descubrimiento de vulnerabilidades. Eso no hace que el modelo sea insignificante, pero sí implica que las comparaciones cara a cara con Mythos deben leerse con cautela.
GPT-5.5: no "GPT-5.5-Cyber", pero sigue siendo muy relevante
GPT-5.5 llegó nueve días después del anuncio de GPT-5.4-Cyber, presentado como un modelo frontera general para tareas complejas de codificación, investigación, análisis de datos, creación de documentos, hojas de cálculo y uso de computadores. OpenAI subraya que GPT-5.5 puede entender antes una tarea desordenada y de varios pasos, usar herramientas con más eficacia, revisar su propio trabajo y continuar a través de la ambigüedad con menos microgestión. Para la ciberseguridad, esa combinación importa porque el trabajo real de seguridad rara vez se reduce a un solo prompt; es una secuencia de leer código, formular hipótesis, ejecutar herramientas, interpretar fallas, proponer correcciones y verificar que el riesgo realmente ha cambiado.
El lanzamiento también destaca mejoras de codificación en Codex, incluyendo un mayor rendimiento en tareas de ingeniería con contexto largo, así como en depuración, pruebas y validación. Según informes, los primeros evaluadores describieron una mayor capacidad para comprender la estructura de un sistema, identificar dónde debe aplicarse una corrección y anticipar cómo podrían verse afectadas otras partes de la base de código. Eso es directamente relevante para la seguridad de las aplicaciones, porque muchos fallos de remediación no ocurren en el momento en que se detecta un error, sino cuando la corrección es incompleta, rompe la lógica circundante, ignora un sumidero o una fuente relacionada o no aborda la causa raíz. Un modelo que mantenga más contexto en una base de código más amplia puede ser más valioso como asistente de remediación que como mero detector.
Puntos de referencia y límites de la comparación
La tabla de evaluación publicada por OpenAI sitúa a GPT-5.5 en 81,8% en CyberGym, frente al 79,0% de GPT-5.4 y al 73,1% de Claude Opus 4.7. CyberGym incluye 1.507 vulnerabilidades históricas en 188 proyectos de software y evalúa principalmente si los agentes pueden generar pruebas de concepto que reproduzcan vulnerabilidades a partir de descripciones y bases de código. Los autores del benchmark subrayan que esto es difícil porque los agentes deben razonar sobre repositorios completos, localizar el código relevante y producir artefactos de reproducción funcionales. Los propios materiales de Anthropic, por separado, afirman que Claude Mythos Preview alcanza un 83,1% en tareas similares de reproducción.
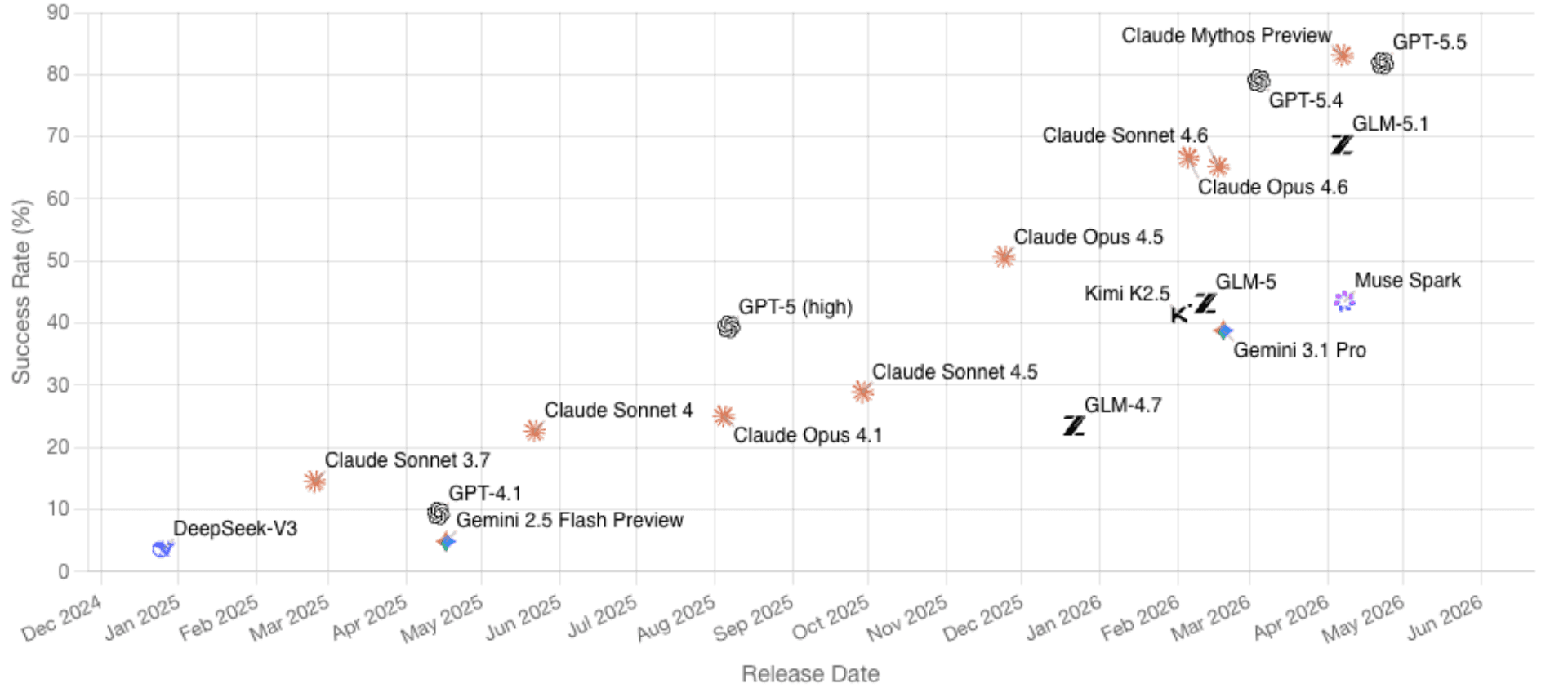
Benchmark de CyberGym (imagen tomada de cybergym.io el 30 de abril de 2026)
Estas cifras no deberían sobreinterpretarse. La tabla compara GPT-5.5 con GPT-5.4, no con GPT-5.4-Cyber, por lo que la posición real de la variante permisiva para ciberseguridad sigue sin estar clara. CyberGym también es un benchmark de reproducción de vulnerabilidades, no una simulación completa de operaciones ofensivas contra objetivos empresariales endurecidos con defensores en vivo, detección en endpoints, controles de identidad y respuesta a incidentes. El comportamiento en producción puede diferir aún más, ya que las evaluaciones de OpenAI se realizaron con un alto esfuerzo de razonamiento en un entorno de investigación.
La imagen se vuelve más clara en evaluaciones más largas y de múltiples pasos que simulan cadenas de ataque completas. El Instituto de Seguridad de IA del Reino Unido (UK AISI), por ejemplo, probó Mythos en un escenario de 32 pasos conocido como el escenario TLO, en el que el modelo completó toda la cadena de ataque de principio a fin en tres de diez intentos y promedió 22 de los 32 pasos en todos los intentos. Ningún modelo de IA evaluado antes había sido capaz de completar ese desafío específico de extremo a extremo.
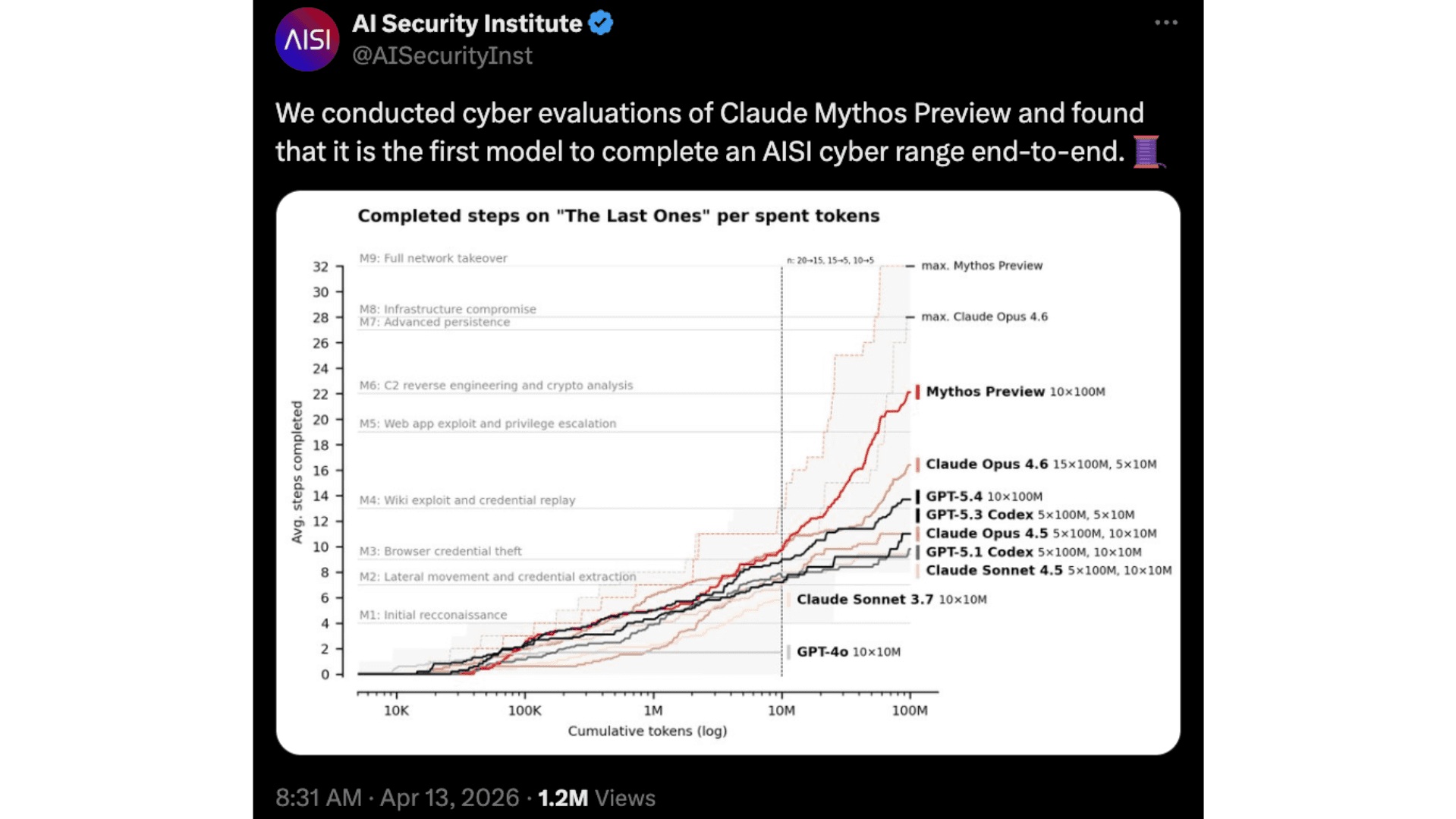
Publicación en X del UK AISI sobre la evaluación de Mythos en el escenario TLO
GPT-5.5 fue sometido a evaluaciones similares de largo alcance. La tarjeta del sistema de OpenAI informa de una tasa de aprobación combinada del 93,33% en ciertos escenarios de cyber range, frente al 73,33% de GPT-5.4 Thinking, atribuyendo la mayor tasa de aprobación a la persistencia en la explotación. Los evaluadores externos reforzaron la imagen: Irregular informó que GPT-5.5 podía proporcionar ayuda significativa a operadores novatos o de nivel intermedio y podía ayudar a operadores muy hábiles en algunos casos, mientras que UK AISI juzgó a GPT-5.5 como el modelo global más fuerte que había probado en tareas cibernéticas estrechas, aunque dentro del margen de error, y encontró que el modelo resolvió de principio a fin un campo de entrenamiento cibernético de red corporativa de 32 pasos en uno de diez intentos.
Alta capacidad, pero por debajo de lo crítico
Bajo el Preparedness Framework de OpenAI, tanto GPT-5.4-Cyber como GPT-5.5 se clasifican como modelos de capacidad de ciberseguridad "Alta", aunque por debajo del umbral "Crítico". Un modelo de capacidad alta puede automatizar operaciones cibernéticas de extremo a extremo contra objetivos razonablemente endurecidos o eliminar de forma significativa los cuellos de botella para descubrir vulnerabilidades operativas relevantes. Un modelo de capacidad crítica podría identificar y desarrollar exploits funcionales de día cero en muchos sistemas críticos del mundo real endurecidos sin intervención humana, o ejecutar estrategias novedosas de ciberataque de extremo a extremo contra objetivos endurecidos, dado solo un objetivo de alto nivel.
OpenAI afirma que GPT-5.5 fue probado contra proyectos de software ampliamente desplegados y endurecidos utilizando alto cómputo en tiempo de prueba y oráculos verificadores, y que no produjo exploits funcionales de severidad crítica en las configuraciones estándar probadas. La compañía ha indicado que, si un modelo futuro llegara al umbral crítico, el desarrollo adicional se pausaría hasta que pudieran implementarse salvaguardas más fuertes. (¿Y Mythos? Permanezcan atentos.)
La respuesta de seguridad de OpenAI para GPT-5.5 también es más estricta que la de modelos generales anteriores, con controles más rígidos en torno a la actividad de mayor riesgo, las solicitudes cibernéticas sensibles y el uso indebido repetido, mientras que el acceso confiable se utiliza para reducir rechazos innecesarios a defensores verificados. En la práctica, OpenAI está dividiendo la experiencia: el acceso amplio a GPT-5.5 viene con clasificadores y supervisión más fuertes; los usuarios cibernéticos de confianza pueden solicitar menos restricciones para el trabajo defensivo legítimo.
Comparación con Claude Mythos y Project Glasswing
El encuadre de Anthropic es más dramático. Como expresamos en nuestra publicación anterior (que te invitamos a leer para más detalles), la compañía describe Claude Mythos Preview como un modelo de lenguaje de propósito general especialmente capaz en tareas de seguridad informática, y afirma que Mythos puede identificar y explotar vulnerabilidades de día cero en todos los sistemas operativos y navegadores web principales cuando se le indica que lo haga. Mythos, supuestamente, también puede realizar ingeniería inversa de exploits en software de código cerrado y convertir vulnerabilidades conocidas pero aún no ampliamente parcheadas en exploits funcionales, con una tasa de éxito reportada superior al 72% en ciertas tareas de generación de exploits.
Project Glasswing es la respuesta de Anthropic al problema del despliegue. En lugar de hacer que Mythos esté ampliamente disponible, Anthropic está dando acceso a socios seleccionados, entre ellos Google, Microsoft y NVIDIA, para identificar y corregir vulnerabilidades en sistemas fundacionales que representan una gran parte de la superficie de ataque compartida. El trabajo abarca la detección local de vulnerabilidades, pruebas de caja negra de binarios, seguridad de endpoints y pruebas de penetración. Anthropic comprometió 100 millones de dólares en créditos de uso del modelo para Glasswing y participantes relacionados, junto con donaciones a organizaciones de seguridad de código abierto, y se comprometió a reportar públicamente lo aprendido en un plazo de 90 días, cuando la divulgación lo permita.
El contraste con OpenAI es, por tanto, en parte técnico y en parte político. Mythos se presenta como un modelo de frontera innovador cuya capacidad cibernética autónoma exige un lanzamiento muy limitado. GPT-5.4-Cyber se presenta como una variante especializada y ciberpermisiva de un modelo existente, situada tras un sistema de verificación más amplio. GPT-5.5 es un modelo general cuyas capacidades cibernéticas son lo bastante fuertes como para requerir salvaguardas mejoradas, pero, según OpenAI, sigue por debajo del umbral crítico. Estas diferencias importan porque los comentarios públicos a menudo tratan a GPT-5.4-Cyber y Mythos como equivalentes directos. Ambos son similares en cuanto a que son modelos controlados, de doble uso y orientados a la defensa; difieren en sus perfiles de capacidad declarados, sus bases de evidencia y sus filosofías de acceso.
Anthropic ha publicado ejemplos más explícitos de descubrimiento de día cero y de generación de exploits, mientras que OpenAI ha publicado más detalles sobre su marco de acceso y sus evaluaciones cibernéticas generales. En los benchmarks, Anthropic dice que Mythos supera sustancialmente a Opus 4.6, y OpenAI informa que GPT-5.5 supera a GPT-5.4 y a Opus 4.7 en CyberGym, pero Opus 4.7 no es Mythos, y GPT-5.4 no es necesariamente GPT-5.4-Cyber. Cualquier tabla de posiciones limpia sería engañosa a menos que se usaran las mismas tareas, entornos de herramientas, configuraciones de rechazo y estándares de verificación.
Los dos modelos de acceso también reflejan apuestas distintas. La apuesta de Anthropic es que ciertas capacidades deberían mantenerse dentro de un consorcio estrecho hasta que mejoren las salvaguardas; la de OpenAI es que la población defensora necesita un acceso más amplio y verificado porque los atacantes no van a esperar. Un lanzamiento restringido reduce el riesgo de distribución, pero puede crear un ecosistema de seguridad a dos niveles en el que solo las organizaciones más grandes reciben las herramientas más potentes; un modelo de acceso de confianza más amplio ayuda a más defensores, pero exige verificación de identidad robusta, supervisión, respuesta ante abusos y gobernanza continua. La pregunta más difícil no es qué empresa suena más responsable; es si cualquiera de los dos enfoques puede escalar sin crear puntos ciegos, dependencias o una ventaja accidental para los atacantes.
La confianza bajo presión: el incidente del proveedor de Mythos
La cuestión de la gobernanza se volvió más aguda después de que Bloomberg informó de que usuarios no autorizados habían accedido a Mythos a través de un entorno de proveedor externo y que dicho acceso supuestamente coincidió con el día en que Anthropic anunció por primera vez sus planes de pruebas limitadas. Anthropic confirmó que estaba investigando el reporte. El incidente, considerado junto con problemas anteriores como fallas en el Model Context Protocol (MCP) y una filtración separada por error humano que expuso unas 500.000 líneas de material de mapas de origen de Claude Code en npm, ilustra un desafío central para todos los laboratorios que construyen IA con capacidad cibernética: el control de acceso, la seguridad de los proveedores y el monitoreo operativo se vuelven parte del caso de seguridad, no simples detalles administrativos.
Dinámica de mercado: ingresos, "criti-hype" y el sector financiero
La competencia entre Anthropic y OpenAI no es solo técnica; también es una contienda por el dominio del mercado y la confianza de los inversionistas. Anthropic, que supuestamente se prepara para una oferta pública inicial, ha visto cómo sus ingresos anualizados han alcanzado los 30.000 millones de dólares, superando la cifra más recientemente informada por OpenAI. Algunos observadores de la industria han etiquetado la estrategia de describir un modelo como "demasiado peligroso para lanzarlo" como "criti-hype", argumentando que advertir en voz alta sobre los peligros extremos de una tecnología puede inflar simultáneamente su valor percibido para los inversores. Se acepte o no ese enfoque, ayuda a explicar por qué cada divulgación sobre Mythos funciona a la vez como mensaje de seguridad y como declaración de marca.
OpenAI ha seguido una dirección distinta al anclar su programa cibernético en asociaciones empresariales. Grandes instituciones financieras, entre ellas Bank of America, BlackRock, BNY, Citi, Goldman Sachs, JPMorgan Chase y Morgan Stanley, se han adherido para apoyar o participar en el programa Trusted Access for Cyber. Estas instituciones gestionan sistemas heredados extensos que son difíciles de sustituir y costosos de asegurar, lo que las convierte en adoptantes tempranos naturales de la defensa asistida por IA a gran escala.
La brecha de acción entre las empresas
Quizás la constatación más importante de 2026 es que la detección de vulnerabilidades en sí misma va camino de convertirse en un bien común; cada vez es más barata, abundante y automatizada. Como ha argumentado Rafael Álvarez, cofundador de Fluid Attacks, el problema principal en la seguridad de aplicaciones rara vez es el descubrimiento; es la disciplina. Las empresas suelen saber exactamente qué está roto y, aun así, no lo corrigen por limitaciones de recursos, mala priorización o falta de contexto.
La avalancha de informes de vulnerabilidades generados por IA añade nueva presión sobre los mantenedores de software. Incluso un hallazgo de alta calidad requiere tiempo humano para validarlo, probarlo y fusionarlo, y la capacidad de los proyectos de código abierto para absorber un gran volumen de hallazgos no escala al mismo ritmo que la capacidad de la IA para sacarlos a la luz. La ventana entre la divulgación y la explotación sigue reduciéndose, volviendo obsoletos los calendarios tradicionales de parcheo cuando un adversario puede pasar del descubrimiento a la explotación en minutos.
El papel del ingeniero de seguridad está cambiando en respuesta. Los ingenieros ya no son los principales "descubridores" de vulnerabilidades; se están convirtiendo en quienes toman decisiones, orquestan agentes de IA, validan sus resultados y emiten llamados de alto impacto sobre la priorización del riesgo. Las plataformas de seguridad más valiosas en este entorno serán aquellas que puedan traducir los hallazgos en decisiones accionables, coordinar la remediación a escala en entornos complejos, proporcionar verificación continua de que una corrección realmente redujo la exposición e integrarse limpiamente en los flujos de trabajo reales de desarrollo y producción.
Lo que los defensores deberían sacar de estos lanzamientos
El Centro Nacional de Ciberseguridad del Reino Unido ha argumentado que la IA de frontera ya está cambiando el costo, la velocidad y la escala de las operaciones cibernéticas tanto para atacantes como para defensores, incluidas tareas como la escritura de código de exploits, la comprensión de la arquitectura de sistemas y el uso de herramientas. El NCSC también sostiene que los defensores conservan ventajas estructurales si se preparan adecuadamente, porque controlan sus propios sistemas, registros, canalizaciones de compilación, arquitectura de identidad y procesos de remediación. Esa ventaja desaparece cuando las organizaciones tratan la IA como un escáner acoplado a un flujo de trabajo de seguridad ya fragmentado.
Para los programas de seguridad de aplicaciones, la lección práctica consiste en construir un circuito cerrado en torno a los hallazgos asistidos por IA. Un flujo de trabajo útil conecta el descubrimiento, la evidencia, el contexto de negocio, la explotabilidad, la propiedad, la guía de remediación, la nueva comprobación y la auditabilidad. Normaliza los hallazgos de múltiples fuentes en lugar de crear otro silo y deja espacio para la revisión humana cuando el costo de estar confiadamente equivocado es alto. También hace seguimiento del rendimiento del modelo en términos específicos de seguridad: falsos positivos, falsos negativos, reproducibilidad, calidad de la corrección, tiempo de validación, tiempo de remediación, tasa de regresión e integración con los flujos de desarrollo existentes.
La cuestión operativa para un CISO no es, por tanto, solo si GPT-5.5 puntúa más alto que GPT-5.4 en CyberGym, o si Mythos es más fuerte en el descubrimiento de vulnerabilidades de día cero, sino si un equipo de seguridad puede usar estos sistemas sin abrumar a los mantenedores, inundar los procesos de CVE, empujar parches inseguros o conceder una confianza excesiva a las salidas de IA no verificadas. Un modelo que acelera el descubrimiento sin reforzar la disciplina de remediación simplemente crea una cola más grande con un lenguaje más impresionante alrededor.
La misma lógica aplica a infraestructura crítica, servicios financieros, salud, telecomunicaciones y tecnología operativa, donde el código heredado, las dependencias frágiles y las largas ventanas de mantenimiento ya limitan la rapidez con que pueden desplegarse las correcciones; si la IA sigue abaratando el descubrimiento mientras el parcheo permanece constreñido, la brecha entre el riesgo conocido y el riesgo resuelto se convierte en una medida central de la resiliencia organizacional.
Recomendaciones estratégicas para líderes
Para ejecutivos y líderes de seguridad que intentan traducir estos anuncios en acción, destacan algunas prioridades:
Adoptar el acceso por niveles desde temprano. Los equipos de seguridad deberían iniciar ahora el proceso de solicitud de Trusted Access for Cyber, para tener acceso verificado a modelos como GPT-5.4-Cyber cuando sea necesario, en lugar de improvisar durante una crisis.
Usar la IA como asistente de triaje, no como oráculo. Aplica los modelos más potentes a casos de uso específicos y estrechos, como la ingeniería inversa binaria para el análisis de malware o la revisión de código con restricciones de política dentro de pipelines de CI/CD, donde los resultados puedan verificarse contra comprobaciones deterministas.
Invertir en el ciclo de remediación, no solo en la detección. Establece un sistema de ciclo cerrado en el que se asigne la propiedad, se haga seguimiento de la remediación, se vuelvan a probar rigurosamente las correcciones y la reducción de la exposición al riesgo sea medible.
Planificar auditoría y supervisión. A medida que los hallazgos automatizados se vuelvan más frecuentes, regímenes regulatorios como la Ley de IA de la UE exigirán una supervisión humana documentada de cómo se usan estos sistemas dentro de la función de seguridad.
El valor se desplaza de encontrar a decidir
GPT-5.4-Cyber y GPT-5.5 muestran que OpenAI se está moviendo hacia una estrategia cibernética por capas: modelos generales más capaces, salvaguardas más sólidas para el acceso amplio y flujos de trabajo más permisivos para defensores verificados. Claude Mythos muestra que Anthropic está dispuesta a presentar las capacidades cibernéticas de frontera como demasiado potentes para un lanzamiento normal, canalizándolas a través de un programa controlado de socios. Estas estrategias difieren en aspectos importantes, pero apuntan hacia la misma estructura de mercado: las capacidades de IA más fuertes se distribuirán cada vez más a través de niveles de confianza, requisitos de seguridad y acceso monitorizado, en lugar de simple disponibilidad pública.
Para proveedores de seguridad y equipos empresariales, el diferenciador se desplazará en consecuencia. La detección seguirá siendo importante, pero perderá valor estratégico si no va acompañada de validación, priorización y remediación verificada. Los programas de seguridad más valiosos serán aquellos que puedan convertir hallazgos abundantes generados por máquinas en decisiones fiables: qué cuestiones importan, quién las asume, cómo deben corregirse, si la corrección es segura y si el riesgo subyacente realmente ha desaparecido. Los agentes de IA pueden asistir en toda esa cadena, pero no eliminan la necesidad de rendición de cuentas, evidencia y juicio humano.
La pregunta para las organizaciones, por tanto, no es si esperar al modelo perfecto, sino si están preparando el enfoque operativo necesario para usar cualquiera de estos sistemas de forma responsable. Eso implica inventariar software y dependencias, reducir la deuda de vulnerabilidades sin resolver, mejorar la propiedad y los SLA de remediación, validar las salidas de IA con herramientas determinísticas y revisión experta, y mantener evidencia de que las correcciones reducen la exposición.
El valor de seguridad no se mide por el número de hallazgos generados; se mide por la cantidad de riesgo reducida. A medida que la IA de frontera acelera el descubrimiento y lo hace más ampliamente disponible, las organizaciones que salgan mejor paradas serán aquellas que puedan absorber el ritmo sin perder el control.
Si crees que tu empresa necesita ayuda para implementar estrategias para abordar estas transformaciones en ciberseguridad con IA, no dudes en contactar a Fluid Attacks.

Empieza ya con la solución de ASPM de Fluid Attacks
Suscríbete a nuestro boletín
Mantente al día sobre nuestros próximos eventos y los últimos blog posts, advisories y otros recursos interesantes.
Otros posts
























