Filosofía
¿Cómo clasificar grupos de forma justa en un CTF?


Chief Data & AI Officer
6 min
La realidad es más sencilla cuando se mira de reojo, es en la mirada cuidadosa donde reside la complejidad. Al menos esa fue mi impresión cuando nuestro equipo de research en Fluid Attacks acudió a mí para construir un mecanismo más apropiado para evaluar los resultados de nuestras competiciones de capture the flag.
Los CTFs, en su forma más común, pueden ser individuales o por equipos. Cuando son entre grupos, suelen enfrentarse universidades, empresas o equipos ad hoc, y para cada competencia se diseña un CTF distinto. Cada evento vive y muere en sí mismo: se compite, se premia y se cierra el capítulo.
Pero entonces surge una pregunta natural: ¿por qué hacer un CTF distinto para cada dimensión (individual y/o equipos), cuando en otros deportes —como el ciclismo, siendo una competencia netamente individual— existen criterios matemáticos que permiten determinar ganadores en diferentes clasificaciones dentro de una misma competencia? ¿Por qué no usar la matemática para medirlo todo dentro de un solo evento?
Más aún, ¿por qué no plantear una competencia de más largo plazo, donde se vea el resultado no solo de un CTF o etapa aislada, sino de una serie de etapas o CTFs a lo largo de todo un año? Una especie de clasificación general acumulada que permita múltiples dimensiones de análisis: ¿Cuál es la mejor universidad formando hackers? ¿Cuál es el mejor país? ¿Cuál es la mejor empresa no especializada en ciberseguridad? ¿Quién mantiene consistencia a lo largo del tiempo? Buscando responder esas preguntas empezamos a desarrollar la idea.
La calificación de los participantes individuales es trivial, todos los competidores entran a la competencia con las mismas condiciones, la misma información y sus resultados reflejan de forma clara su performance en la competición, sin embargo, cuando pensamos en presentar rankings por agrupaciones (países, empresas y universidades) la cuestión se vuelve más compleja y ciertamente interesante.
El asunto central de la evaluación por grupos (y de esta entrada de blog) es cómo agregar los resultados de los participantes, pues, dependiendo del mecanismo, los resultados pueden variar ampliamente y con ellos las estrategias óptimas. Veamos algunas de las aproximaciones más comunes y sus consecuencias.
Nota: Para las simulaciones a continuación usaré una distribución escalada de 0-100 basada en los puntajes originales de la edición 2025 del CTF (Fluid Attacks' CTF - Desafío LATAM).
Promedio
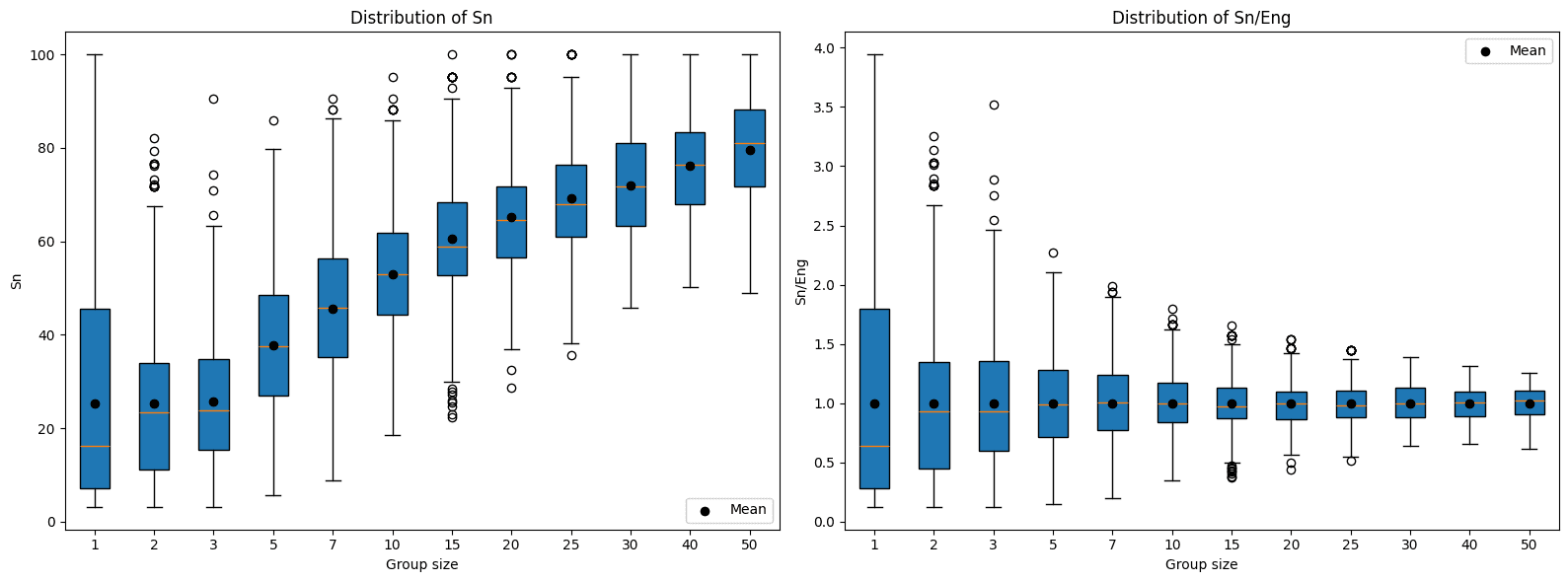
Cuando pensamos en agregaciones, probablemente la principal es el promedio, mirado de reojo da una noción del performance general del grupo y controla por el número de participantes, sin embargo una mirada profunda revela dos problemas, el primero de ellos es que cuando el grupo es pequeño la varianza es alta, haciendo difícil determinar si el performance es representativo del grupo o mera casualidad. Este problema es fácil de evidenciar si simulamos grupos de n participantes y estudiamos el comportamiento de sus puntajes:
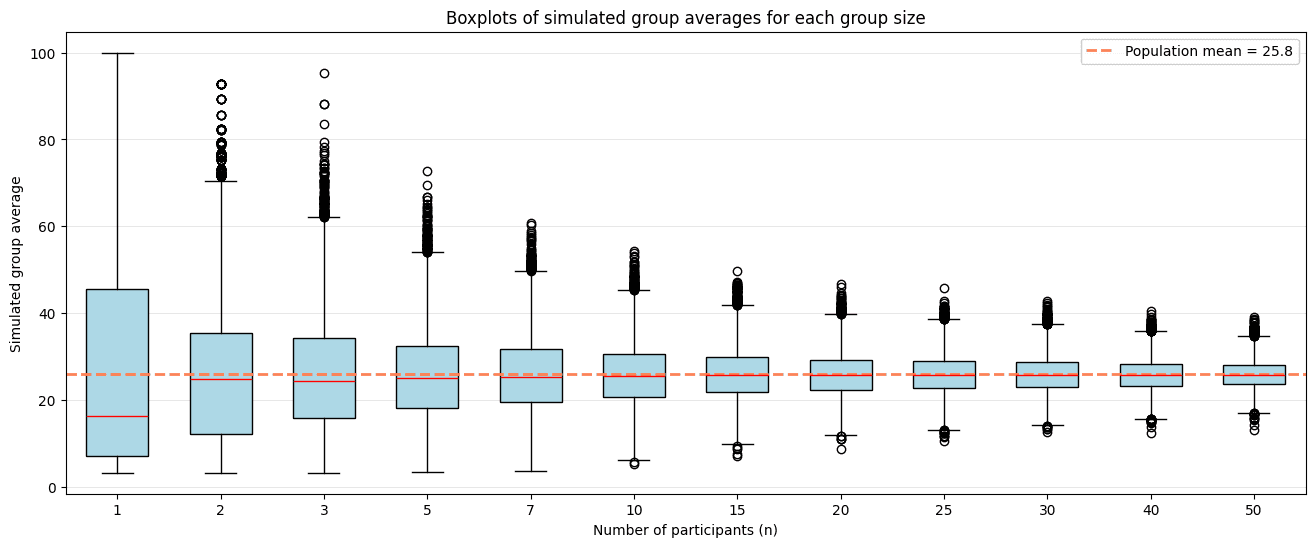
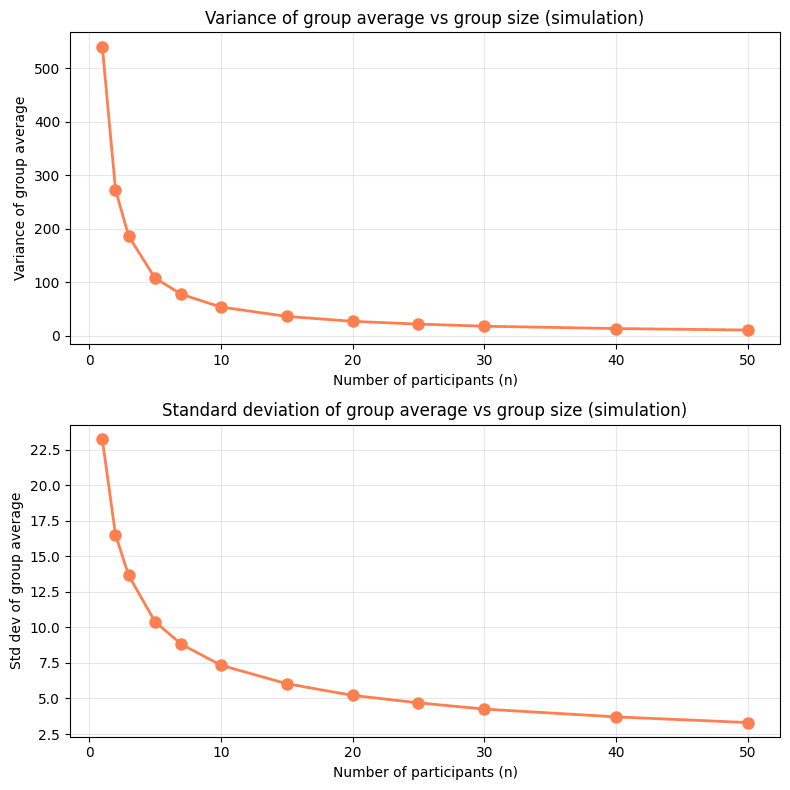
El segundo problema proviene de los incentivos que genera. La estrategia ganadora en un escenario guiado por el promedio es que las organizaciones limiten sus participantes para que solo los mejores puedan asistir, dejando a participantes menos experimentados por fuera de la competencia. Como organizadores del evento, buscamos que la participación sea tan amplia como sea posible y este principio debe reflejarse incluso en el mecanismo de agregación de puntajes.
Top 3
Calificar el performance del grupo por el promedio de sus mejores tres participantes es una alternativa que no desmotiva la participación de los participantes menos experimentados, sin embargo no es ajeno a problemas derivados del tamaño del grupo.
¿Por qué top 3 y no top 4 o top 5? La elección del 3 no es completamente arbitraria, pero tampoco es mágica. Tres participantes permiten capturar una noción de “masa crítica” de talento dentro del grupo, evitando que un único outlier defina toda la clasificación, como ocurriría con un top 1, y sin exigir una profundidad excesiva que favorecería desproporcionadamente a los grupos más grandes, como podría suceder con un top 5 o superior. Es un punto intermedio razonable entre representatividad y equidad. Ahora bien, ¿qué ocurre con grupos de menos de tres integrantes? En esos casos, el promedio se calcula con los participantes disponibles.
Con el esquema de top 3 también existen problemas, por un lado la desviación estándar es incluso más alta que en el caso del promedio, generando aún más incertidumbre cuando los grupos son pequeños. Otro problema, todavía más interesante, es que el score esperado crece con el número de participantes, es decir, grupos más grandes tienen mayor probabilidad de tener top scorers entre sus filas, generando una ventaja injustificada a favor de los grupos con mayor número de participantes.
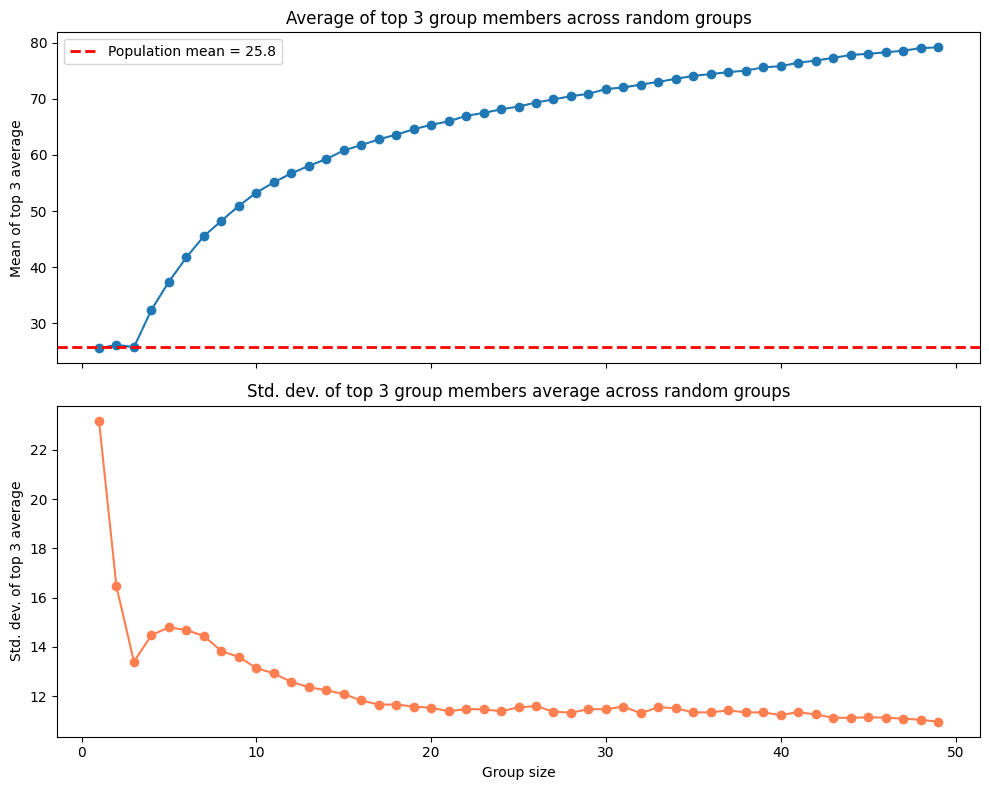
Top 3 sobre lo esperado con contracción bayesiana
Muchas veces los problemas complejos requieren soluciones complejas. Para este caso buscamos cumplir con un conjunto de restricciones derivadas de las aproximaciones vistas anteriormente:
Controlar la alta varianza cuando los grupos son pequeños
Evitar desventajas derivadas de tener pocos jugadores
No desincentivar la participación de jugadores menos experimentados
Facilitar la agregación de múltiples CTF para generar rankings de largo plazo
El algoritmo se construye sobre el score promedio de los tres mejores jugadores del grupo y sobre él construye ciertos refinamientos para cumplir con las restricciones mencionadas, la fórmula general es:
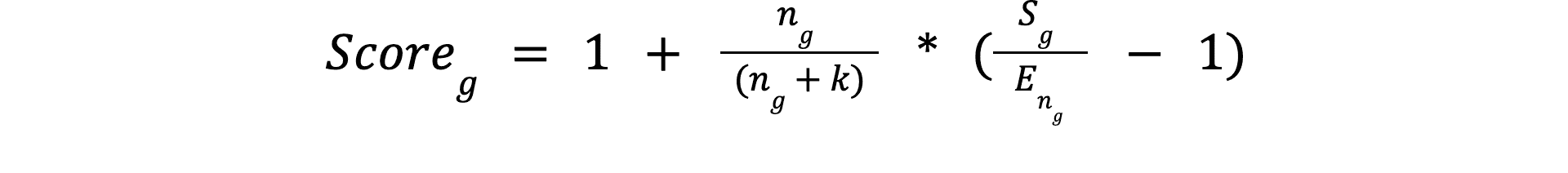
Sg: El promedio de score del top 3 de los participantes del grupong: La cantidad de participantes en el grupoEng: El valor esperado del score del top 3 de los participantes para un grupo de tamañonk: El número de participantes mínimo que hace que los resultados del grupo sean confiables
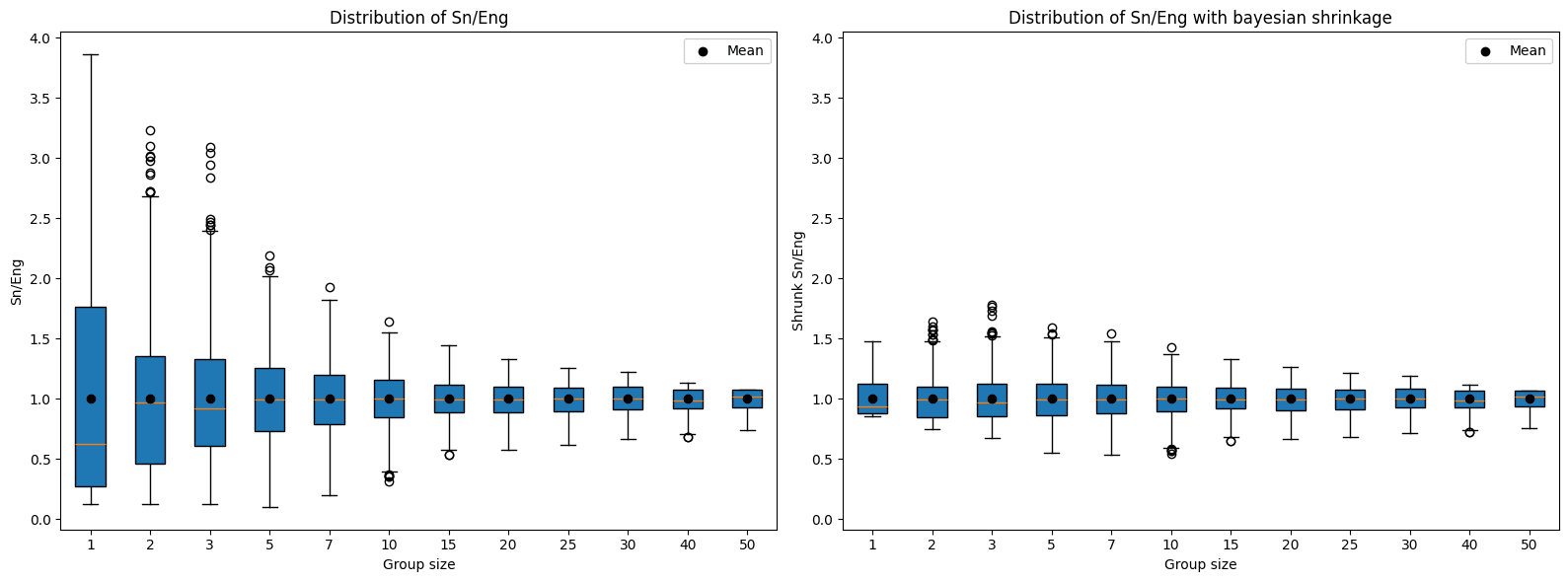
El refinamiento sobre Sg va en dos vías, la primera intenta lidiar con la ventaja de tener más participantes que enunciamos en la sección anterior, para esto se utiliza Eng con el objetivo de normalizar el score observado en función del score esperado para un grupo de la misma magnitud.
Eng se calcula por medio de una simulación de montecarlo, en la cual se forman grupos aleatorios de n integrantes de la lista de resultados del CTF, se calcula el puntaje promedio del top 3 y se repite el experimento múltiples veces (1.000 para efectos de esta entrada) promediando los resultados.
La segunda vía intenta lidiar con la incertidumbre derivada de tener pocos participantes, para ese fin se usa la contracción bayesiana, que en pocas palabras, consiste en acercar los valores al promedio cuando la muestra es pequeña. k es el parámetro que determina la fuerza de la contracción, cuando n < k, a medida que aumenta la distancia también aumenta la atracción hacia el promedio (que en este caso es 1, por efecto de la normalización Sg/Eng); mientras que cuando n > k, aumentos en la distancia hacen que la fuerza de atracción disminuya, haciendo que el impacto sobre el score sea marginal. En la práctica k = 5 representa una masa crítica sin convertirse en un parámetro demasiado exigente.
Agregación a lo largo de múltiples CTFs
Si la intención es construir una competencia de más largo plazo, surge una nueva pregunta: ¿cómo se agregan los resultados de varios CTFs?
La aproximación más directa es sumar scores normalizados de cada evento. Dado que el mecanismo ya produce un score relativo (centrado en 1 y ajustado por tamaño), los resultados de distintos CTFs son comparables entre sí.
La construcción de un sistema de puntuación para agrupaciones en el CTF nos demostró que, si bien la solución simple es tentadora, los incentivos y la equidad que buscamos como organizadores exigen una aproximación más robusta.
Lo que comenzó como un problema técnico terminó revelándose como una pregunta filosófica: ¿qué significa realmente “ser el mejor”? ¿Es el destello de un genio aislado? ¿La profundidad de un equipo numeroso? ¿La constancia en el tiempo?
El algoritmo de Top 3 sobre lo esperado con contracción bayesiana representa ese punto de encuentro necesario entre la estadística y la filosofía de la competencia. No pretende eliminar la incertidumbre (porque competir es, en esencia, abrazarla), pero sí domesticarla lo suficiente para que el ranking refleje el verdadero performance de los grupos, independientemente de su tamaño, y promueva la participación de todos.
Al final, la matemática no reemplaza el espíritu del CTF; lo enmarca. Nos permite tener un solo evento, múltiples dimensiones y una historia que se escribe no en un fin de semana, sino a lo largo del tiempo.

Empieza ya con el PTaaS de Fluid Attacks
Suscríbete a nuestro boletín
Mantente al día sobre nuestros próximos eventos y los últimos blog posts, advisories y otros recursos interesantes.
Otros posts
























