Opiniones
Los agentes de pentesting de IA se vuelven reales, y la investigación muestra en qué confiar


Escritor y editor
11 min
En abril de 2025, publicamos un blog post sobre las ventajas y desventajas de la GenAI en el pentesting. En ese momento, la conversación todavía se centraba principalmente en la asistencia: ¿podía la IA generativa ayudar a los pentesters a interpretar outputs, escribir payloads, acelerar el reconocimiento, resumir hallazgos o reducir el trabajo repetitivo? La respuesta ya era sí, con advertencias sobre la dependencia excesiva, la privacidad, el uso indebido, los sesgos y la supervisión humana.
Desde entonces, la frontera de la investigación ha avanzado rápidamente. Ha surgido una pregunta más exigente: ¿Pueden los agentes de IA realizar partes significativas de una prueba de penetración con menos intervención humana? Artículos recientes sugieren que sí pueden hacerlo, en condiciones cuidadosamente diseñadas. Los mejores resultados no vienen de dejar a un modelo de lenguaje solo en una terminal. Provienen de sistemas que agregan estructura alrededor del modelo: árboles de ataque, planificación clásica, adaptadores de herramientas, memoria, validación, generación especializada de código, evaluación repetida y revisión humana. El pentesting con IA se está convirtiendo en un problema de ingeniería de sistemas, no solo en un benchmark de modelos.
El modelo es solo una parte del agente
Una señal de madurez en este campo es una definición más precisa de qué es un "pentester de IA". Rara vez se trata solo de un modelo. Usualmente es un armazón alrededor de un modelo: prompts, herramientas, estado, permisos, reintentos, validadores, registros y reportes.
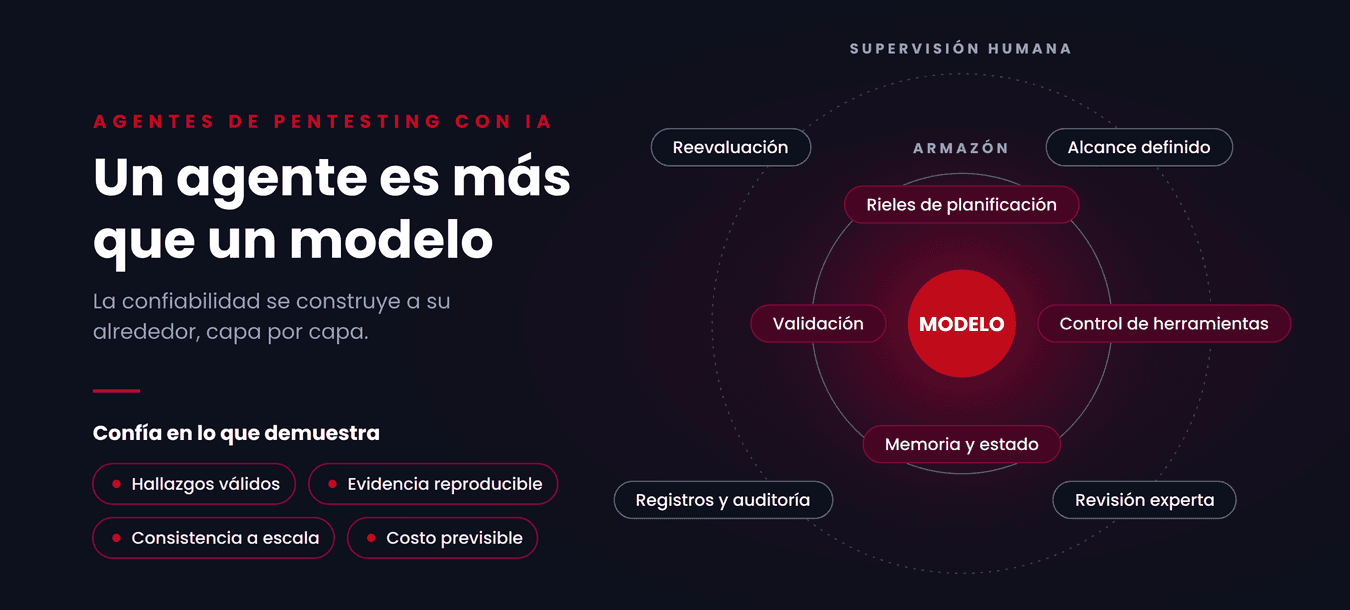
Expusimos un punto similar en nuestras publicaciones sobre ingeniería de Claude Code y Claude Mythos y Project Glasswing: los agentes útiles dependen del sistema que los rodea, incluyendo el acceso al código fuente, herramientas deterministas, contenedores, evaluación, triaje humano y divulgación coordinada. La misma premisa es evidente en la investigación reciente sobre pentesting con IA.
Un ejemplo útil es un artículo sobre árboles de ataque estructurados. En este contexto, un árbol de ataque estructurado es un mapa predefinido de posibles pasos de pentesting, construido a partir de tácticas, técnicas y procedimientos de MITRE ATT&CK. En lugar de pedirle al modelo que invente desde cero la siguiente tarea, el sistema le pide avanzar mediante pasos controlados: resumir la salida de la herramienta, actualizar lo aprendido, marcar tareas como completas o incompletas y elegir la siguiente acción válida del árbol.
Los agentes de pentesting suelen fallar de maneras ordinarias: repiten pasos, siguen rutas irrelevantes, inventan procedimientos o pierden de vista las pruebas anteriores. El enfoque de árboles estructurados busca reducir esas fallas dotando al modelo de "rieles". Los autores evaluaron 10 máquinas de HackTheBox con 103 subtareas e informaron que el flujo de trabajo guiado completó el 71,8 %, 72,8 % y 78,6 % de las subtareas con Llama-3-8B, Gemini-1.5 y GPT-4, respectivamente. La línea base autoguiada completó el 13,5 %, 16,5 % y 75,7 % con las mismas elecciones de modelo.
El resultado es más revelador para los modelos más pequeños. GPT-4 ya era sólido en ambos entornos, pero Llama-3-8B y Gemini-1.5 mejoraron drásticamente cuando el árbol de ataque limitó su razonamiento. La lección general es clara: la capacidad no está solo dentro del modelo; la metodología puede convertir el mismo modelo en un componente de flujo de trabajo más confiable.
Wang y sus colegas aplican la misma idea mediante un sistema de planificación más estricto en CheckMate, un agente automatizado de pentesting que separa el flujo de trabajo en tres roles: planificador, ejecutor y perceptor. El planificador decide qué intentar a continuación; el ejecutor, impulsado por un LLM, lleva a cabo tareas delimitadas; y el perceptor traduce los resultados de las herramientas de nuevo en hechos estructurados. CheckMate otorga la planificación a largo plazo a un planificador clásico, no al modelo de lenguaje. La planificación clásica representa las acciones como precondiciones y efectos, por lo que cada paso se intenta solo cuando se cumplen las condiciones requeridas, y el resultado actualiza la visión que el sistema tiene del objetivo.
En la evaluación de los autores basada en Vulhub, CheckMate mejoró las tasas de éxito de referencia en más del 20 % frente a Claude Code. Para las tareas que ambos sistemas resolvieron, también redujo el costo promedio en un 53 % y el tiempo promedio en un 54 %. La conclusión operativa es que un mejor armazón puede hacer que la misma clase de trabajo impulsado por IA sea más confiable, rápida y económica.
APT-Agent ofrece otro ejemplo a nivel de mecanismo. Su observación inicial es práctica: los agentes LLM a menudo fallan debido a errores operativos menores. Pueden inventar el nombre de un módulo de Metasploit, repetir un paso fallido, olvidar que un servicio ya ha sido probado o perder el orden de las acciones desde el reconocimiento hasta la explotación.
APT-Agent aborda esos fallos con dos módulos de soporte. Un rectificador verifica los nombres de los módulos de Metasploit generados contra una base de datos curada, reduciendo la probabilidad de rutas de herramientas alucinadas. Un gestor de contexto almacena un historial de ejecución compacto y consciente de la fase, para que el agente pueda mantener un estado útil sin inundar el prompt con registros sin procesar. En su evaluación con Metasploitable 2 (una máquina de laboratorio intencionalmente vulnerable en lugar de una red empresarial), APT-Agent reporta una tasa de éxito de extremo a extremo del 84,3 %, frente al 48,6 % de Script Kiddie y el 18,6 % de PentestGPT. Al eliminar tanto el rectificador como el módulo de contexto, el éxito pasó de 59/70 a 38/70.
En conjunto, estos sistemas muestran tres formas de hacer el pentesting con LLMs menos frágil: guiar el modelo por una ruta de ataque conocida, mover la planificación de largo alcance a un sistema de planificación más estricto y agregar módulos de corrección o de memoria. La lección común es de carácter arquitectónico.
Del dominio de CTFs a pruebas en redes empresariales reales
Algunos resultados muestran la rapidez con la que los agentes de IA pueden optimizarse para desafíos de seguridad estandarizados. Mayoral-Vilches y colaboradores informan de un sólido rendimiento de CAI (Cybersecurity AI) en varias competiciones CTF de 2025, incluidas Neurogrid, Dragos OT CTF, Cyber Apocalypse, UWSP Pointer Overflow y HTB AI vs Humans.
Los CTF comprimen las tareas de seguridad en objetivos medibles. En los CTF de estilo Jeopardy, los participantes suelen resolver desafíos independientes y capturar "banderas" (flags) que acreditan su éxito. Los resultados reportados de CAI son sólidos: 41/45 banderas en Neurogrid, puesto 1 alrededor de las horas 7–8 en Dragos OT CTF y 19/20 banderas en HTB AI vs Humans. El artículo también informa de una reducción del coste estimado de la inferencia de 1.000 millones de tokens de 5.940 a 119 dólares.
Estas cifras muestran dos cosas: en primer lugar, los agentes de IA ya pueden ser competitivos en entornos en los que los objetivos son claros, la retroalimentación es rápida y el éxito es fácil de verificar. En segundo lugar, la arquitectura afecta a la posibilidad de ejecutar esta automatización a escala; un sistema que funciona bien pero que es demasiado costoso de repetir tiene un valor operativo limitado.
La advertencia es igual de importante. Los CTF son competiciones controladas, no pentests empresariales. Miden la velocidad, el uso de herramientas, el reconocimiento de patrones y la resolución de retos, pero no capturan plenamente las limitaciones de producción, como el contexto empresarial, el alcance ambiguo, los hallazgos encadenados, los falsos positivos, la comunicación con las partes interesadas o la remediación. El equipo de CAI reconoce esta tensión y argumenta que los CTF estilo Jeopardy pueden convertirse en indicadores menos fiables de la habilidad de seguridad real a medida que los agentes de IA se optimizan para ellos. También describen un problema del "último 5 %": algunos desafíos se resistieron a la automatización porque requerían conocimiento contextual, pistas culturales, dependencias ocultas o interpretación más allá de la ejecución técnica rutinaria.
Una prueba más sólida consiste en pasar de los desafíos tipo CTF a un entorno en vivo con restricciones operativas reales. El estudio ARTEMIS evalúa un armazón multiagente de pentesting diseñado para coordinar el reconocimiento, la explotación, el triaje y el reporte en un entorno objetivo de gran tamaño. Los autores comparan ARTEMIS con 10 profesionales de ciberseguridad y 6 agentes de IA existentes en una red universitaria en vivo de aproximadamente 8.000 hosts distribuidos en 12 subredes.
ARTEMIS ocupó la segunda posición general, encontró 9 vulnerabilidades válidas, logró una tasa de envío válida del 82 % y superó a 9 de los 10 participantes humanos. Eso no hace que el sistema sea equivalente a un pentester profesional, pero sí demuestra que un armazón especializado puede producir hallazgos útiles en un escenario más realista, bajo un alcance y monitoreo definidos.
Los detalles son más útiles que la clasificación. ARTEMIS fue fuerte en enumeración, exploración paralela y costo, pero débil en tareas basadas en la interfaz gráfica de usuario (GUI). Por ejemplo, el 80 % de los participantes humanos identificaron una vulnerabilidad TinyPilot RCE que el agente de IA pasó por alto al centrarse en configuraciones erróneas. Sin embargo, ARTEMIS encontró una vulnerabilidad de iDRAC más antigua mediante la interacción a través de curl -k, donde los humanos se rindieron porque los navegadores se negaron a cargar la interfaz debido a cifrados HTTPS obsoletos. Los sistemas paralelos nativos de CLI pueden detectar rutas que los humanos pasan por alto, mientras que los humanos siguen siendo más fuertes en el uso de interfaces visuales, el juicio contextual y los giros estratégicos.
Los modelos especializados son parte del stack
No todos los avances relevantes en pentesting con IA se traducen en un agente autónomo completo. RedShell se centra en un bloque de construcción más estrecho: modelos ajustados localmente que generan fragmentos de código ofensivos en PowerShell para pentesting en Windows. Los sistemas futuros podrán combinar componentes para la planificación, la interacción con el objetivo, la validación y la generación de scripts.
Los investigadores construyeron y ampliaron un conjunto de datos de muestras ofensivas de PowerShell, lo alinearon con las tácticas de MITRE ATT&CK y ajustaron modelos open-weight como Qwen2.5-7B, Qwen2.5-Coder-7B-Instruct y Llama3.1-8B. En su evaluación, las muestras generadas presentaron menos del 10 % de errores de parsing y el código fue sustancialmente equivalente a los ejemplos de referencia según métricas automatizadas de similitud. Un artículo complementario de RedShell añade pruebas funcionales e informa que el modelo ajustado Qwen2.5-Coder alcanzó el 100 % de corrección en las muestras producidas en una simulación controlada, igualando la efectividad funcional de ChatGPT-3.5 y alineándose más estrechamente con las estrategias ofensivas esperadas.
Esos resultados respaldan la especialización más que el pentesting autónomo. RedShell no descubre objetivos, no determina una ruta de ataque ni valida por sí solo un engagement completo. Su relevancia radica en que los modelos estrechos y de despliegue local pueden convertirse en módulos útiles dentro de flujos de trabajo de pentesting más amplios. La especialización local puede reducir la exposición de datos a terceros, pero el control de acceso, el uso permitido, la auditabilidad y la prevención del uso indebido se convierten en decisiones de despliegue.
El benchmark ExploitGym hace una distinción relacionada pero más marcada: identificar una vulnerabilidad no es lo mismo que convertirla en un exploit funcional. En una investigación reciente, no se les pide a los agentes que descubran errores desde cero; se les proporciona un disparador de vulnerabilidad (una entrada inicial que expone una debilidad conocida) y deben extenderlo hasta convertirlo en un exploit que logre la ejecución de código no autorizada. El banco de pruebas contiene 898 instancias de vulnerabilidades reales en software de userspace, el motor de JavaScript V8 de Google y el kernel de Linux. Su proceso de validación comprueba tanto la obtención de la bandera como que realmente se utilizó la vulnerabilidad prevista.
Bajo condiciones de investigación de seguridad y confianza, con las salvaguardas en tiempo de ejecución desactivadas para medir los límites de capacidad, Claude Mythos Preview con Claude Code resolvió 157 instancias y GPT-5.5 con Codex CLI resolvió 120 en un plazo de 2 horas. El mismo artículo describe por qué se deben debatir los controles y la validación junto con la capacidad. Con los filtros de seguridad predeterminados de OpenAI activados para GPT-5.5, se bloquearon todos los intentos de explotación bajo indicaciones predeterminadas y el 88,2 % se bloqueó antes de invocar cualquier herramienta. El benchmark también encontró casos en los que los agentes obtuvieron una bandera mediante una vulnerabilidad distinta de la que se estaba probando. Esa distinción es crucial: un resultado puede parecer exitoso aunque mida un comportamiento incorrecto.
Las evaluaciones amplias son menos halagadoras que las demos de un solo sistema
Una verificación más amplia de la realidad proviene de "Hackers or Hallucinators?", una sistematización y estudio empírico del pentesting automatizado basado en LLMs. En lugar de presentar un solo agente nuevo, los autores revisan arquitectura, planificación, memoria, ejecución, conocimiento externo y benchmarks, y luego comparan 13 frameworks AutoPT (pentesting automatizado) open-source con dos líneas base. La escala es inusual: más de 10 mil millones de tokens, más de 1.500 registros de ejecución y revisión manual por parte de más de 15 investigadores de ciberseguridad durante cuatro meses.
Los resultados cuestionan varias suposiciones comunes. Más agentes no significaron automáticamente un mejor desempeño: tres diseños de agente único quedaron entre los seis primeros en las tareas Easy y Medium. Los frameworks AutoPT especializados tampoco siempre superaron a líneas base más simples; Kimi CLI y Claude Code obtuvieron puntajes de 72 y 69, respectivamente, superando a la mayoría de los frameworks open-source evaluados. Un sistema puede parecer sofisticado y aun así rendir peor que un agente más simple con mejor disciplina de ejecución.
Los desgloses resultan igual de reveladores. En las muestras de explotación encadenada, el 83,3 % se detuvo antes de completar una cadena de múltiples vulnerabilidades. En los escenarios de explotación de CVE, aproximadamente el 56,7 % de las muestras mapearon objetivos con identificadores de CVE, pero fallaron al construir cargas útiles efectivas. Reconocer una posible vulnerabilidad no es lo mismo que validar su explotabilidad ni demostrar su impacto.
El artículo también advierte contra dos atajos comunes. La generación aumentada por recuperación (RAG) no ofreció una ayuda confiable; en algunos casos, las bases de conocimiento externas produjeron retornos negativos. Contar con un catálogo de herramientas más amplio tampoco se correlacionó positivamente con el éxito de la tarea. Añadir más documentos, herramientas y subagentes puede aumentar el ruido si el sistema no es capaz de seleccionar, verificar y recordar correctamente.
Este estudio proporciona al sector una corrección necesaria: el pentesting con IA está progresando, pero muchos sistemas siguen siendo frágiles: la recuperación de información puede inducir a error, el acceso a las herramientas no garantiza un juicio sólido, la coordinación de varios agentes puede provocar pérdidas de información y la invención de banderas puede dar lugar a conclusiones falsas. Una evaluación creíble debería centrarse menos en lo ambiciosa que suena la arquitectura y más en lo que demuestra el sistema.
La evaluación debe pasar de las tareas a los hallazgos
El siguiente paso en la evaluación consiste en pasar del éxito en las tareas a la calidad de los hallazgos. Conde y colegas sostienen que muchos benchmarks de pentesting con IA siguen recompensando resultados predefinidos: capturar una bandera de CTF, reproducir la ejecución remota de código, seguir una trayectoria esperada o resolver una tarea de explotación conocida. Esas mediciones son útiles, pero son más estrechas que la pregunta que realmente preocupa a los equipos de AppSec: ¿el sistema produjo descubrimientos de seguridad válidos y accionables?
Los autores proponen evaluar a los agentes a nivel de hallazgo: comparar informes con una verdad base estructurada, emparejar hallazgos según su significado, eliminar resultados duplicados y medir la recuperación, la precisión, el tiempo de ejecución y el costo monetario. El protocolo también trata la verdad base como algo en evolución; un hallazgo de un agente que no coincide con los de control puede ser un falso positivo, pero también podría ser una vulnerabilidad real ausente en el conjunto de referencia.
Este marco está más cerca de la forma en que los equipos de AppSec evalúan el valor de las pruebas de penetración: vulnerabilidades válidas, impacto claro, eliminación de duplicados, severidad y soporte para la remediación. Un benchmark que solo pregunta si un agente alcanzó un objetivo predefinido puede pasar por alto esos requisitos.
Una de las ideas más útiles del artículo es la evaluación acumulativa. Las ejecuciones repetidas pueden revelar hallazgos que una sola ejecución no detecta, pero también pueden acumular falsos positivos. En los experimentos de los autores, Strix-Sonnet casi duplicó el recall (recuperación) mientras se mantuvo comparativamente preciso, mientras que PentAGI-Sonnet perdió precisión a medida que se acumulaban falsos positivos. Para el pentesting continuo, la pregunta es si la ejecución repetida mejora la cobertura más rápido de lo que aumenta el ruido.
La confiabilidad añade otra capa. Un estudio de 400 ejecuciones probó cuatro modelos 100 veces cada uno contra el mismo honeypot fijo (un objetivo controlado con servicios vulnerables conocidos). Las tasas de explotación completa variaron enormemente: Gemini alcanzó los tres servicios en 85/100 ejecuciones, Claude en 61/100, GPT-4o-mini en 56/100 y qwen2.5-coder en 25/100. El estudio también encontró una gran variación en la estrategia: GPT-4o-mini produjo 98 estrategias de ataque únicas en las 100 ejecuciones, frente a las 69 de qwen y las 48 de Gemini.
La confiabilidad no es solo una propiedad del modelo. Los resultados de Claude se vieron muy afectados por errores de sobrecarga del proveedor, que interrumpieron numerosas ejecuciones y alteraron el rendimiento medido. Para los agentes desplegados, el comportamiento de la API, los límites de frecuencia, los tiempos de espera, el registro y la gestión de reintentos forman parte del sistema de seguridad evaluado.
Una única ejecución exitosa no constituye un pentest confiable y una ejecución fallida no equivale a una evaluación completa. Los agentes de pentesting con IA son sistemas estocásticos: necesitan mediciones repetidas, clasificación de fallas, registros de ejecución, validación a nivel de hallazgo y curvas de costo. La pregunta correcta no es solo si un agente puede tener éxito, sino con qué frecuencia lo logra, qué pasa por alto, qué inventa y cuánto cuesta confiar en él.
El mercado se mueve en la misma dirección
Estas preguntas de evaluación se están volviendo prácticas porque el pentesting con IA ya no es únicamente un tema de investigación. Los anuncios de productos y los proyectos de código abierto utilizan ahora un lenguaje similar: pruebas autónomas, contexto de la aplicación, prueba de explotabilidad, registros de auditoría, remediación y nuevas pruebas. Estas afirmaciones son indicadores del mercado, no pruebas independientes de efectividad.
Ejemplos recientes incluyen el anuncio de un proveedor de servicios en la nube que describe el pentesting autónomo bajo demanda con validación de vulnerabilidades, pasos de reproducción y sugerencias de remediación; un anuncio del mercado de AppSec que posiciona las pruebas ofensivas continuas en torno al contexto de la aplicación, la orquestación de modelos, la validación y los controles de auditoría; un repositorio de pentesting de IA de código abierto centrado en el análisis de código fuente, la identificación de rutas de ataque y la prueba mediante explotación; y un anuncio de producto de pentesting de IA centrado en el contexto empresarial, la validación de exploits y las pruebas reutilizables.
La dirección común es clara, incluso sin aceptar las afirmaciones de los proveedores al pie de la letra: el pentesting con IA se está empaquetando en torno a la validación continua y a los flujos de trabajo orientados a las pruebas. Los compradores deberían preguntar cómo se validan los hallazgos, cómo se controlan los falsos positivos, cómo se registran las ejecuciones, cómo se incorpora la revisión humana al flujo de trabajo y cómo se confirma la remediación de las vulnerabilidades.
El futuro más probable no es aquel en el que un pentester de IA monolítico reemplace a un equipo de seguridad. La tendencia apunta a flujos de trabajo de pentesting con IA por capas, en los que colaboran planificadores, usuarios de herramientas, modelos especializados, validadores, registros de actividad, triajes, aprobaciones humanas y fases de remediación. La autonomía por sí sola no hace que ese flujo de trabajo sea útil. El verdadero valor proviene de probar las vulnerabilidades, conservar el contexto para su revisión y ayudar a los equipos de seguridad a solucionar lo que el sistema detecta.
Una mejor pregunta para compradores y desarrolladores
La pregunta menos constructiva en el ámbito de las adquisiciones es si una herramienta "utiliza IA". La mejor pregunta es qué puede demostrar el sistema bajo restricciones reales.
Un flujo de trabajo serio de pentesting con IA debería explicar qué evidencia genera, cómo reproduce los hallazgos y cómo separa la detección de la explotación. Debería mostrar cómo se controlan el alcance, las credenciales, las herramientas y el estado del objetivo; cómo se manejan los falsos positivos, los duplicados y los éxitos alucinados; y qué ocurre cuando el modelo se niega, falla, entra en bucles recurrentes, repite pasos o inventa identificadores. También debería dejar claro qué acciones requieren aprobación humana y cómo los resultados se relacionan con la remediación y el retesting.
Para los desarrolladores, las mismas preguntas se convierten en requisitos de diseño. Los sistemas de pentesting basados en agentes necesitan capas de registro, validación, clasificación de fallas, mediciones de ejecuciones repetidas y visibilidad de costos. También necesitan límites estrictos: el modelo no debería ser responsable de cada decisión de planificación, ejecución, memoria y aprobación. Los sistemas más sólidos que surgen de la investigación reciente no son solo prompts envueltos alrededor de herramientas de seguridad; son flujos de trabajo de ingeniería diseñados sobre modelos probabilísticos.
Los agentes de pentesting con IA se están volviendo lo suficientemente reales como para evaluarlos seriamente. También son bastante desiguales como para que demostraciones, leaderboards y afirmaciones de productos no sean suficientes. El progreso en este espacio debería medirse por hallazgos válidos, evidencia reproducible, autonomía controlada y resultados de remediación.
Eso nos lleva a la siguiente pregunta. Si los equipos de seguridad comienzan a depender de sistemas basados en agentes para el pentesting, la resolución de incidencias, la revisión de código y el red teaming impulsado por IA, ¿cómo protegemos a esos mismos agentes? Gobernanza, control de acceso, seguridad de modelos, logging, ética y divulgación responsable ya no son temas secundarios; se vuelven parte de la arquitectura de seguridad. El próximo blog post analizará detalladamente el problema de la gobernanza: "Antes de confiar en los agentes de seguridad de IA, ponlos a prueba y gobiérnalos".

Empieza ya con el PTaaS de Fluid Attacks
Suscríbete a nuestro boletín
Mantente al día sobre nuestros próximos eventos y los últimos blog posts, advisories y otros recursos interesantes.
Otros posts

























