Filosofia
Como classificar grupos de forma justa em um CTF?


Chief Data & AI Officer
6 min
A realidade é mais simples quando olhamos por cima; é no olhar atento que mora a complexidade. Pelo menos essa foi a minha impressão quando o nosso time de research na Fluid Attacks me procurou para construir um mecanismo mais adequado de avaliação dos resultados das nossas competições de capture the flag.
Os CTFs, na sua forma mais comum, podem ser individuais ou por equipes. Quando são entre grupos, geralmente competem universidades, empresas ou equipes montadas para a ocasião, e cada competição tem um CTF diferente. Cada evento vive e morre em si mesmo: compete-se, premia-se e encerra-se o capítulo.
Mas aí surge uma pergunta natural: por que criar um CTF diferente para cada dimensão (individual e/ou por equipes), se em outros esportes, como o ciclismo, que é uma competição essencialmente individual, existem critérios matemáticos que permitem determinar vencedores em diferentes classificações dentro da mesma prova? Por que não usar a matemática para medir tudo dentro de um único evento?
Mais ainda: por que não propor uma competição de mais longo prazo, em que o resultado não venha apenas de um CTF ou etapa isolada, mas de uma série de etapas ou CTFs ao longo de um ano inteiro? Uma espécie de classificação geral acumulada que permite múltiplas dimensões de análise: Qual é a melhor universidade na formação de hackers? Qual é o melhor país? Qual é a melhor empresa que não é especializada em cibersegurança? Quem mantém a consistência ao longo do tempo? Buscando responder a essas perguntas, começamos a desenvolver a ideia.
A pontuação dos participantes individuais é trivial; todos os competidores entram na competição nas mesmas condições, com as mesmas informações, e os seus resultados refletem de maneira clara o seu desempenho. No entanto, quando pensamos em apresentar rankings por agrupamentos (países, empresas e universidades), a questão fica mais complexa e, sem dúvida, mais interessante.
O ponto central da avaliação por grupos (e deste blog post) é como agregar os resultados dos participantes, porque, dependendo do mecanismo, os resultados podem variar muito e, junto com eles, as estratégias ótimas. Vamos algumas das abordagens mais comuns e as suas consequências.
Nota: Para as simulações a seguir, utilizarei uma distribuição normalizada de 0 a 100 com base nas pontuações originais da edição de 2025 (Fluid Attacks' CTF - LATAM Challenge).
Média
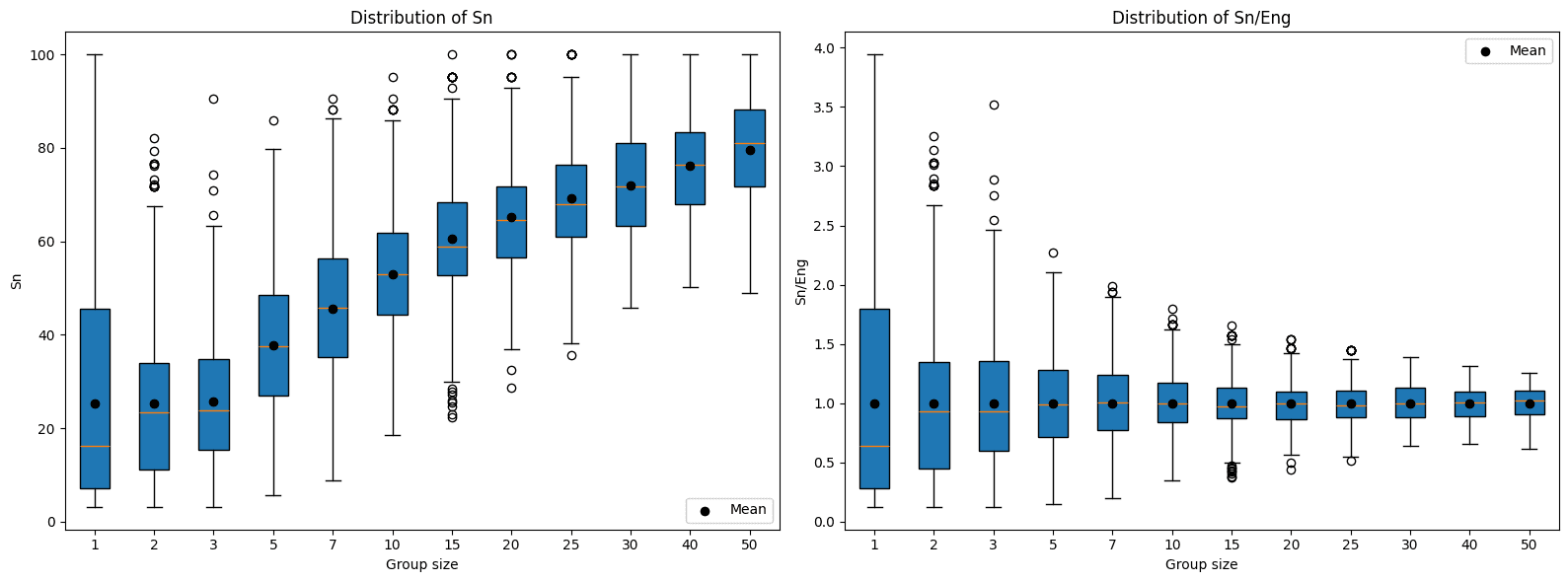
Quando pensamos em agregações, provavelmente a principal delas é a média. De relance, ela dá uma noção do desempenho geral do grupo e controla pelo número de participantes. Porém, um olhar mais atento revela dois problemas. O primeiro é que, quando o grupo é pequeno, a variância é alta, o que dificulta saber se o desempenho é de fato do grupo ou mero acaso. Esse problema fica fácil de demonstrar se simularmos grupos de n participantes e observarmos o comportamento das suas pontuações:
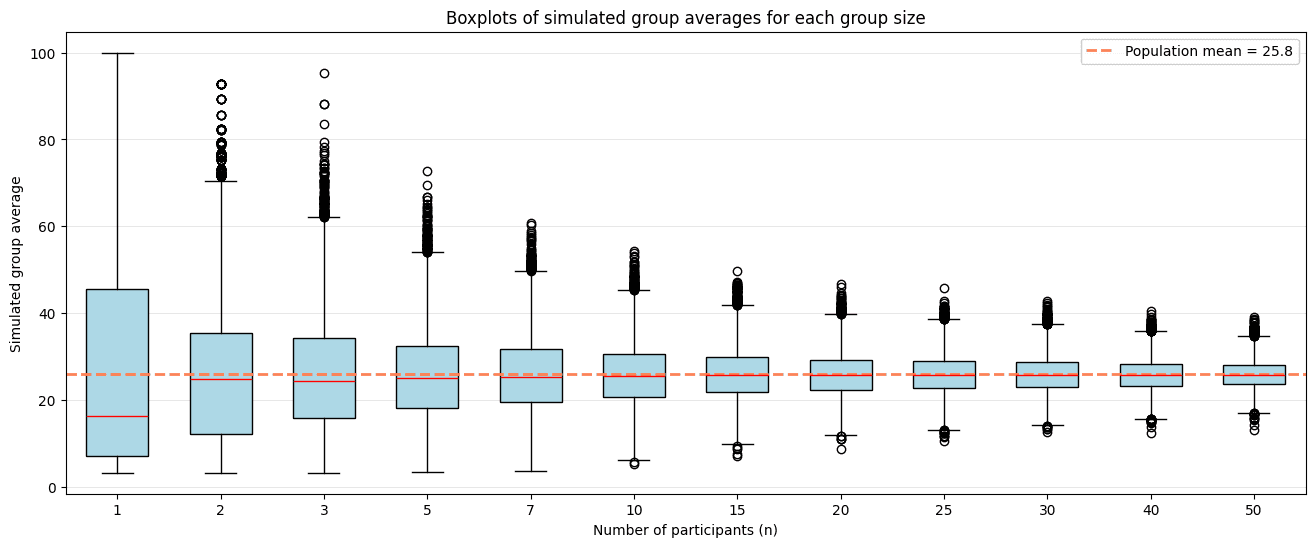
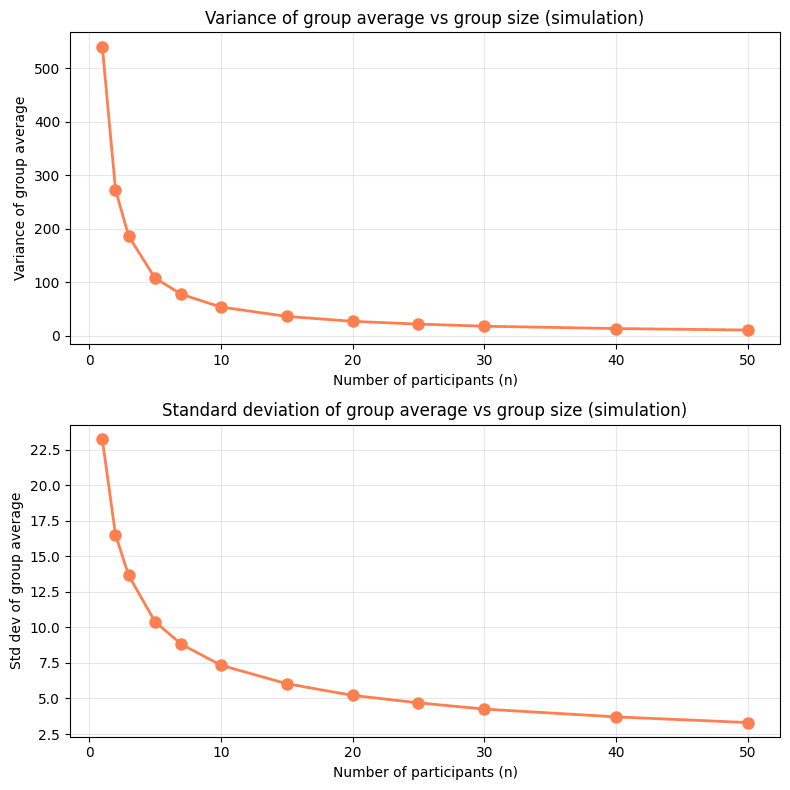
O segundo problema vem dos incentivos que a média gera. A estratégia vencedora em um cenário guiado pela média é que as organizações limitem os seus participantes para que apenas os melhores compareçam, deixando os menos experientes de fora da competição. Como organizadores do evento, queremos que a participação seja a mais ampla possível, e esse princípio precisa se refletir inclusive no mecanismo de agregação de pontuações.
Top 3
Avaliar o desempenho do grupo pela média dos seus três melhores participantes é uma alternativa que não desestimula a participação dos menos experientes; no entanto, ela também não está livre de problemas ligados ao tamanho do grupo.
Por que top 3 e não top 4 ou top 5? A escolha do 3 não é totalmente arbitrária, mas tampouco é mágica. Três participantes permitem capturar uma noção de "massa crítica" de talento dentro do grupo, impedindo que um único outlier defina toda a classificação, como aconteceria com um top 1, e sem exigir uma profundidade excessiva que favoreceria desproporcionalmente os grupos maiores, como poderia acontecer com um top 5 ou mais. É um ponto intermediário razoável entre representatividade e equidade. Mas e quando o grupo tem menos de três integrantes? Nesses casos, a média é calculada com os participantes disponíveis.
Com o esquema do top 3 também existem problemas. Por um lado, o desvio padrão é ainda maior do que no caso da média, gerando mais incerteza quando os grupos são pequenos. Outro problema, ainda mais interessante, é que a pontuação esperada cresce junto com o número de participantes, ou seja, grupos maiores têm mais probabilidade de ter top scorers nas suas fileiras, criando uma vantagem injustificada a favor dos grupos com mais participantes.
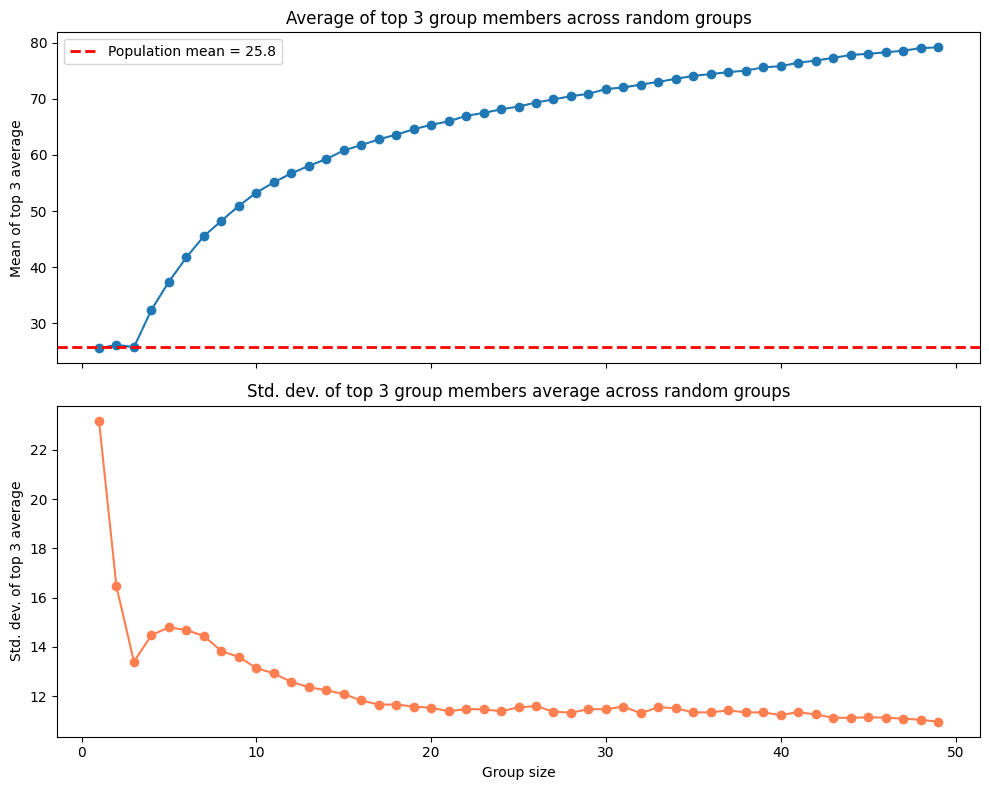
Top 3 sobre o esperado com contração bayesiana
Os problemas complexos costumam exigir soluções complexas. Para este caso, buscamos atender a um conjunto de restrições derivadas das abordagens vistas anteriormente:
Controlar a alta variância quando os grupos são pequenos
Evitar desvantagens decorrentes de ter poucos participantes
Não desestimular a participação dos jogadores menos experientes
Facilitar a agregação de múltiplos CTFs para gerar rankings de longo prazo
O algoritmo parte da média das pontuações dos três melhores jogadores do grupo e aplica certos refinamentos para atender às restrições mencionadas. A fórmula geral é:
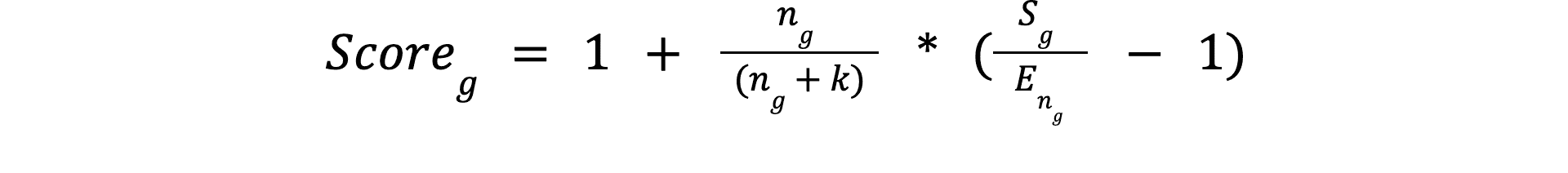
Sg: Média das pontuações do top 3 dos participantes do grupong: Número de participantes no grupoEng: Pontuação esperada do top 3 para um grupo de tamanhonk: Número mínimo de participantes para que os resultados do grupo sejam confiáveis
O refinamento sobre Sg segue por dois caminhos. O primeiro tenta lidar com a vantagem de ter mais participantes que mencionamos na seção anterior. Para isso, utiliza-se Eng com o objetivo de normalizar a pontuação observada em função da pontuação esperada para um grupo do mesmo tamanho.
O cálculo de Eng é feito por meio de uma simulação de Monte Carlo, na qual se formam grupos aleatórios de n integrantes a partir da lista de resultados do CTF, calcula-se a pontuação média do top 3 e repete-se o experimento diversas vezes (1.000, para fins deste post), tirando a média dos resultados.
O segundo caminho tenta lidar com a incerteza decorrente de ter poucos participantes. Para isso se utiliza a contração bayesiana, que, em poucas palavras, consiste em aproximar os valores da média quando a amostra é pequena. k é o parâmetro que determina a intensidade da contração. Quando n < k, conforme a distância aumenta, a atração em direção à média (que neste caso é 1, por efeito da normalização Sg/Eng) também aumenta; já quando n > k, aumentos na distância fazem com que a força de atração diminua, tornando o impacto sobre a pontuação marginal. Na prática, k = 5 representa uma massa crítica sem se tornar um parâmetro excessivamente exigente.
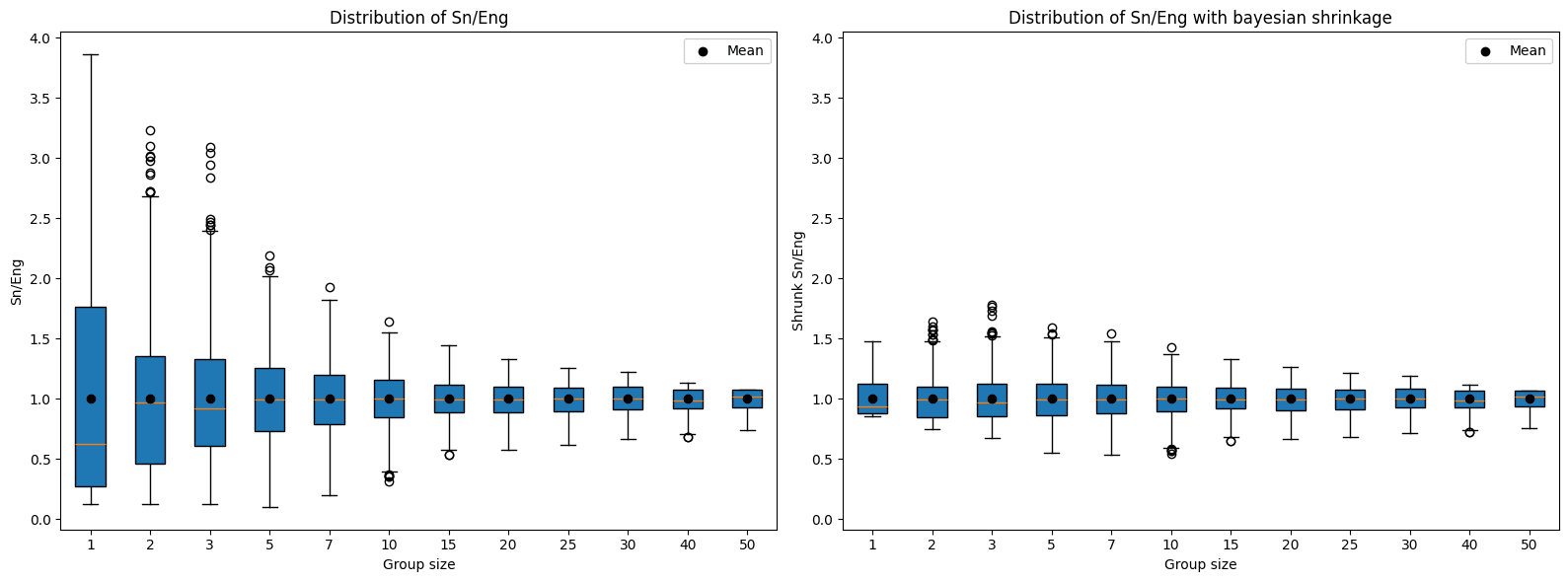
Agregação ao longo de múltiplos CTFs
Se a intenção é construir uma competição de mais longo prazo, surge uma nova pergunta: Como agregar os resultados de vários CTFs?
A abordagem mais direta é somar as pontuações normalizadas de cada evento. Como o mecanismo do top 3 já produz uma pontuação relativa (centrada em 1 e ajustada pelo tamanho), os resultados de diferentes CTFs são comparáveis entre si.
A construção de um sistema de pontuação para agrupamentos no CTF nos mostrou que, embora a solução simples seja tentadora, os incentivos e a equidade que buscamos como organizadores exigem uma abordagem mais robusta.
O que começou como um problema técnico acabou se revelando uma questão filosófica: O que realmente significa "ser o melhor"? É o brilho de um gênio isolado? A profundidade de uma equipe numerosa? A consistência ao longo do tempo?
O algoritmo Top 3 sobre o esperado com contração bayesiana representa esse ponto de encontro necessário entre a estatística e a filosofia da competição. Ele não pretende eliminar a incerteza (porque competir é, em essência, abraça-la), mas sim domesticá-la o suficiente para que o ranking reflita o verdadeiro desempenho dos grupos, independentemente do seu tamanho, e promova a participação de todos.
No fim das contas, a matemática não substitui o espírito do CTF; ela o enquadra. Ela nos permite ter um único evento, múltiplas dimensões e uma história que se escreve não em um fim de semana, mas ao longo do tempo.

Comece agora com o PTaaS da Fluid Attacks
Assine nossa newsletter
Mantenha-se atualizado sobre nossos próximos eventos e os últimos posts do blog, advisories e outros recursos interessantes.
Outros posts
























