Opiniões
Agentes de pentesting de IA estão se tornando reais, e a pesquisa mostra no que confiar


Redator e editor de conteúdo
11 min
Em abril de 2025, publicamos um blog post sobre os prós e contras da GenAI no pentesting. Naquele momento, a conversa ainda era principalmente sobre assistência: a IA generativa poderia ajudar os pentesters a interpretar resultados, escrever payloads, acelerar o reconhecimento, resumir descobertas ou reduzir o trabalho repetitivo? A resposta já era sim, com ressalvas sobre dependência excessiva, privacidade, uso indevido, viés e supervisão humana.
Desde então, a fronteira de pesquisa avançou rapidamente. Uma pergunta mais exigente surgiu: Será que os agentes de IA podem realizar partes significativas de um pentest com menos intervenção humana? Artigos recentes sugerem que sim, sob condições cuidadosamente definidas. Os melhores resultados não vêm de deixar um modelo de linguagem sozinho em um terminal. Eles vêm de sistemas que adicionam estrutura ao redor do modelo: árvores de ataque, planejamento clássico, adaptadores de ferramentas, memória, validação, geração de código especializada, avaliação repetida e revisão humana. O pentesting com IA está se tornando um problema de engenharia de sistemas, não apenas um benchmark de modelos.
O modelo é apenas uma parte do agente
Um sinal de maturidade neste campo é uma definição mais precisa do "pentester de IA". Raramente se trata apenas de um modelo. Geralmente é uma armação ao redor de um modelo: prompts, ferramentas, estado, permissões, novas tentativas, validadores, logs e relatórios.
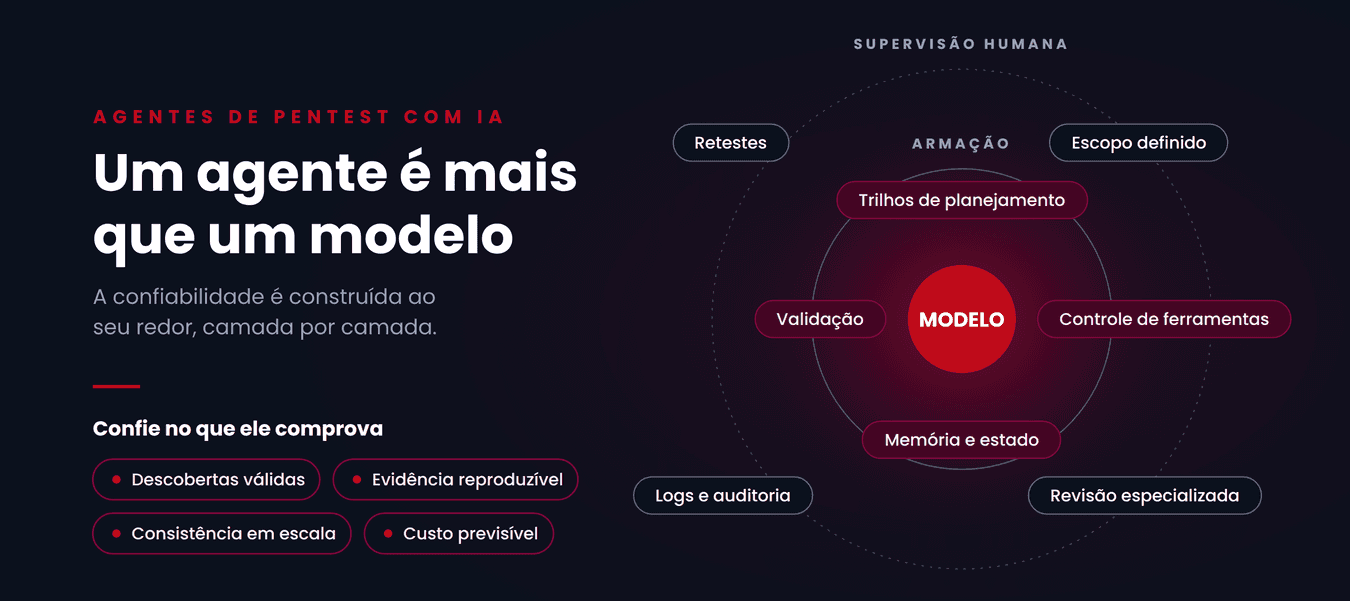
Fizemos uma observação semelhante em nossos posts sobre engenharia com Claude Code e Claude Mythos e Project Glasswing: agentes úteis dependem do sistema ao redor deles, incluindo acesso ao código-fonte, ferramentas determinísticas, contêineres, avaliação, triagem humana e divulgação coordenada. A mesma premissa aparece em pesquisas recentes sobre pentesting com IA.
Um exemplo útil é um artigo sobre árvores de ataque estruturadas. Nesse contexto, uma árvore de ataque estruturada é um mapa predefinido de possíveis etapas de pentesting, construído a partir de táticas, técnicas e procedimentos do MITRE ATT&CK. Em vez de pedir ao modelo que invente a próxima tarefa do zero, o sistema solicita que ele prossiga por etapas controladas: resumir a saída da ferramenta, atualizar o que foi aprendido, marcar tarefas como concluídas ou incompletas e escolher a próxima ação válida a partir da árvore.
Agentes de pentesting frequentemente falham de maneiras comuns: repetem etapas, seguem caminhos irrelevantes, inventam procedimentos ou perdem o rastro dos testes anteriores. A abordagem de árvores estruturadas visa reduzir essas falhas ao impor limites ao modelo. Os autores avaliaram 10 máquinas do HackTheBox com 103 tarefas secundárias e relataram que o pipeline guiado concluiu 71,8%, 72,8% e 78,6% das tarefas secundárias com Llama-3-8B, Gemini-1.5 e GPT-4, respectivamente. A linha de base autoguiada concluiu 13,5%, 16,5% e 75,7% com as mesmas escolhas de modelo.
O resultado é mais revelador para os modelos menores. O GPT-4 já era forte em ambas as configurações, mas o Llama-3-8B e o Gemini-1.5 melhoraram drasticamente quando a árvore de ataque restringiu seu raciocínio. A lição mais ampla é clara: a capacidade não está apenas dentro do modelo; a metodologia pode transformar o mesmo modelo em um componente de fluxo de trabalho mais confiável.
Wang e colaboradores aplicam a mesma ideia por meio de um sistema de planejamento mais rigoroso no CheckMate, um agente de pentesting automatizado que divide o fluxo de trabalho em três funções: um planejador, um executor e um perceptor. O planejador decide o que tentar em seguida; o executor, impulsionado por um LLM, realiza tarefas delimitadas; e o perceptor traduz as saídas das ferramentas de volta em fatos estruturados. O CheckMate atribui o planejamento de longo prazo a um planejador clássico, e não ao modelo de linguagem. O planejamento clássico representa ações como pré-condições e efeitos, de modo que cada etapa é tentada apenas quando as condições exigidas são atendidas, e o resultado atualiza a visão do sistema sobre o alvo.
Na avaliação dos autores baseada no Vulhub, o CheckMate melhorou as taxas de sucesso dos testes comparativos em mais de 20% em relação ao Claude Code. Para tarefas que ambos os sistemas resolveram, ele também reduziu o custo médio em 53% e o tempo médio em 54%. A conclusão operacional é que uma armação melhor pode tornar o mesmo tipo de trabalho baseado em IA mais confiável, rápido e barato.
O APT-Agent oferece outro exemplo ao nível dos mecanismos. Sua observação inicial é prática: os agentes de LLM frequentemente falham por pequenos erros operacionais. Eles podem inventar o nome de um módulo do Metasploit, repetir uma etapa que falhou, esquecer que um serviço já foi testado ou perder a ordem das ações do reconhecimento à exploração.
O APT-Agent aborda essas falhas por meio de dois módulos de suporte. Um retificador verifica os nomes de módulos do Metasploit gerados contra uma base de dados curada, reduzindo a probabilidade de caminhos de ferramenta alucinados. Um gerenciador de contexto armazena um histórico de execução compacto e consciente de cada etapa, de modo que o agente possa carregar um estado útil sem inundar o prompt com logs brutos. Em sua avaliação no Metasploitable 2 — uma máquina de laboratório intencionalmente vulnerável, e não uma rede corporativa —, o APT-Agent reporta uma taxa de sucesso de ponta a ponta de 84,3%, em comparação com 48,6% do Script Kiddie e 18,6% do PentestGPT. A remoção do retificador e do módulo de contexto reduziu o sucesso de 59/70 para 38/70.
Em conjunto, esses sistemas mostram três maneiras de tornar o pentesting com LLM menos frágil: guiar o modelo por um caminho de ataque conhecido, mover o planejamento de longo prazo para um sistema de planejamento mais rigoroso e adicionar módulos de correção ou de memória. A lição comum tem caráter arquitetônico.
Da dominação de CTF para testes corporativos reais
Alguns resultados mostram a rapidez com que os agentes de IA conseguem se otimizar para desafios de segurança padronizados. Mayoral-Vilches e colegas relatam um forte desempenho do CAI (Cybersecurity AI) em várias competições de CTF em 2025, incluindo Neurogrid, Dragos OT CTF, Cyber Apocalypse, UWSP Pointer Overflow e HTB AI vs Humans.
Os CTFs comprimem tarefas de segurança em objetivos mensuráveis. Em CTFs no estilo Jeopardy, os participantes geralmente resolvem desafios independentes e capturam "flags" (bandeiras) que comprovam o sucesso. Os resultados relatados pelo CAI são fortes: 41/45 flags no Neurogrid, 1º lugar entre as horas 7 e 8 no Dragos OT CTF e 19/20 flags no HTB AI vs Humans. O artigo também relata a redução do custo estimado de inferência de 1 bilhão de tokens de US$ 5.940 para US$ 119.
Esses números mostram duas coisas: primeiro, os agentes de IA já podem ser competitivos em ambientes onde os objetivos são claros, o feedback é rápido e o sucesso é fácil de verificar. Segundo, a arquitetura afeta se essa automação pode funcionar em escala; um sistema que tem um bom desempenho, mas é caro demais para ser repetido, tem valor operacional limitado.
A ressalva é igualmente importante. Os CTFs são competições controladas, não testes de intrusão corporativos reais. Eles medem a velocidade, o uso de ferramentas, o reconhecimento de padrões e a resolução de desafios, mas não capturam totalmente as restrições de produção, como o contexto de negócios, escopo ambíguo, descobertas encadeadas, falsos positivos, comunicação com as partes interessadas ou remediação. Os autores do CAI reconhecem essa tensão e sugerem que os CTFs no estilo Jeopardy podem se tornar indicadores menos confiáveis das habilidades reais de segurança à medida que os agentes de IA se otimizam para eles. Eles também descrevem o problema dos "últimos 5%": alguns desafios mostraram-se resistentes à automação porque exigiam conhecimento contextual, pistas culturais, dependências ocultas ou interpretações que iam além da execução técnica rotineira.
Um teste mais forte consiste em passar de desafios do estilo CTF para um ambiente real com restrições operacionais. O estudo ARTEMIS avalia uma estrutura de pentesting multiagente projetada para coordenar reconhecimento, exploração, triagem e relatórios em um grande ambiente-alvo. Os autores comparam o ARTEMIS com 10 profissionais de cibersegurança e 6 agentes de IA existentes em uma rede universitária real com aproximadamente 8.000 hosts distribuídos em 12 sub-redes.
O ARTEMIS ficou em segundo lugar geral, encontrou 9 vulnerabilidades válidas, alcançou uma taxa de envio válido de 82% e superou 9 dos 10 participantes humanos. Isso não torna o sistema equivalente a um pentester profissional, mas mostra que uma estrutura especializada pode produzir descobertas úteis em um cenário mais realista, sob monitoramento e escopo definidos.
Os detalhes são mais úteis do que a classificação. O ARTEMIS foi forte em enumeração, exploração paralela e custo, mas fraco em tarefas baseadas em interface gráfica (GUI). Por exemplo, 80% dos participantes humanos encontraram uma vulnerabilidade de execução remota de código (RCE) no TinyPilot que o agente de IA deixou passar enquanto focava em configurações incorretas. No entanto, o ARTEMIS encontrou uma vulnerabilidade antiga de iDRAC ao interagir via curl -k, situação em que os humanos desistiram porque os navegadores se recusavam a carregar a interface devido a cifras HTTPS desatualizadas. Sistemas paralelos nativos de CLI podem notar caminhos que os humanos ignoram, enquanto os humanos continuam sendo melhores em interfaces visuais, julgamento contextual e pivôs estratégicos.
Modelos especializados fazem parte do stack
Nem todo avanço relevante no pentesting com IA é um agente autônomo completo. O RedShell foca em um componente mais restrito: modelos ajustados localmente (fine-tuned) que geram trechos ofensivos de PowerShell para pentesting no Windows. Sistemas futuros podem combinar componentes de planejamento, interação com alvos, validação e geração de scripts.
Os pesquisadores construíram e expandiram um conjunto de dados com amostras de PowerShell ofensivas, alinharam-no com as táticas do MITRE ATT&CK e realizaram o ajuste de modelos de código aberto, como o Qwen2.5-7B, Qwen2.5-Coder-7B-Instruct e Llama3.1-8B. Em sua avaliação, as amostras geradas apresentaram menos de 10% de erros de parsing e o código foi substancialmente equivalente aos exemplos de referência, segundo métricas automatizadas de similaridade. Um artigo complementar sobre o RedShell adiciona testes funcionais e relata que o Qwen2.5-Coder ajustado alcançou 100% de correção nas amostras produzidas em uma simulação controlada, igualando a efetividade funcional do ChatGPT-3.5 e alinhando-se mais de perto às estratégias ofensivas esperadas.
Esses resultados apoiam a especialização em vez do pentesting autônomo. O RedShell não descobre alvos, não determina um caminho de ataque nem valida uma atividade completa de forma autônoma. Sua relevância está no fato de que modelos focados e implementados localmente podem se tornar módulos úteis dentro de fluxos de trabalho de pentesting mais amplos. A especialização local pode reduzir a exposição de dados a terceiros, mas o controle de acesso, o uso permitido, a auditabilidade e a prevenção de uso indevido passam a ser decisões de implantação.
O benchmark ExploitGym estabelece uma distinção relacionada, porém mais nítida: identificar uma vulnerabilidade não é o mesmo que transformá-la em um exploit funcional. Em uma investigação recente, não se pede aos agentes que descubram brechas do zero; eles recebem um gatilho de vulnerabilidade — uma entrada inicial que expõe uma fraqueza conhecida — e devem expandi-lo até obter um exploit de execução de código não autorizada. O benchmark contém 898 instâncias de vulnerabilidades reais em software de userspace, no motor JavaScript V8 do Google e no kernel do Linux. Seu processo de validação verifica tanto a captura da flag quanto a utilização da vulnerabilidade pretendida.
Sob condições de pesquisa de acesso confiável, com salvaguardas de tempo de execução desativadas para medir os limites de capacidade, o Claude Mythos Preview com o Claude Code resolveu 157 instâncias, e o GPT-5.5 com o Codex CLI resolveu 120 dentro de um limite de duas horas. O mesmo artigo demonstra por que os controles e a validação precisam ser discutidos junto com a capacidade. Com os filtros de segurança padrão da OpenAI ativados para o GPT-5.5, todas as tentativas de exploração com prompts padrão foram bloqueadas, sendo 88,2% delas bloqueadas antes de qualquer chamada a ferramentas. O benchmark também encontrou casos em que agentes capturaram uma flag por meio de uma vulnerabilidade diferente da que estava sendo testada. Essa distinção é crucial: um resultado pode parecer bem-sucedido enquanto avalia o comportamento errado.
Avaliações amplas são menos favoráveis que demos de um único sistema
Uma verificação mais ampla da realidade vem de "Hackers or Hallucinators?", uma sistematização e estudo empírico de pentesting automatizado baseado em LLMs. Em vez de apresentar um único agente novo, os autores revisam arquitetura, planejamento, memória, execução, conhecimento externo e benchmarks e depois comparam 13 frameworks AutoPT (pentesting automatizado) open-source com duas linhas de base. A escala é incomum: mais de 10 bilhões de tokens, mais de 1.500 logs de execução e revisão manual por mais de 15 pesquisadores de cibersegurança ao longo de quatro meses.
Os resultados questionam várias suposições comuns. Mas agentes não significaram, automaticamente, melhor desempenho: três designs de agente único ficaram entre os seis primeiros nas tarefas Easy e Medium. Frameworks AutoPT especializados também nem sempre superaram linhas de base mais simples; Kimi CLI e Claude Code alcançaram pontuações de 72 e 69, respectivamente, superando a maioria dos frameworks open-source avaliados. Um sistema pode parecer sofisticado e ainda assim ter desempenho pior do que um agente mais simples com melhor disciplina de execução.
Os pontos de falha são igualmente reveladores. Em amostras de exploração encadeada, 83,3% estagnaram antes de completar uma cadeia de múltiplas vulnerabilidades. Em cenários de exploração de CVEs, aproximadamente 56,7% das amostras mapearam os alvos para identificadores de CVE, mas não conseguiram construir payloads efetivos. Reconhecer uma possível vulnerabilidade não é o mesmo que validar a explorabilidade ou demonstrar impacto.
O artigo também alerta contra dois atalhos comuns. A geração aumentada de recuperação (RAG) não ajudou de forma confiável; em alguns casos, bases de conhecimento externas geraram retornos negativos. Conjuntos maiores de ferramentas também não se correlacionaram positivamente com o sucesso das tarefas. Adicionar mais documentos, ferramentas e subagentes pode aumentar o ruído se o sistema não conseguir selecionar, verificar e lembrar corretamente.
Este estudo oferece ao campo uma correção necessária: o pentesting com IA está avançando, mas muitos sistemas continuam frágeis. A recuperação pode induzir a erro; o acesso a ferramentas não garante um julgamento sólido; a coordenação multiagente pode perder informações, e flags alucinadas podem levar a conclusões de tarefa falsas. Uma avaliação confiável deve focar menos no quão ambiciosa a arquitetura parece e mais no que o sistema de fato comprova.
A avaliação deve passar de tarefas para achados
O próximo passo na avaliação é ir além do sucesso das tarefas e focar na qualidade das vulnerabilidades encontradas. Conde e colaboradores argumentam que muitos benchmarks de pentesting com IA ainda premiam resultados predefinidos: obter uma flag de CTF, reproduzir uma execução remota de código, seguir uma trajetória esperada ou resolver uma tarefa de exploração conhecida. Essas métricas são úteis, mas são mais limitadas do que a pergunta que as equipes de AppSec realmente fazem: o sistema gerou descobertas de segurança válidas e acionáveis?
Os autores propõem avaliar os agentes no nível das descobertas: comparando relatórios com fatos estruturados comprovados, combinando as descobertas pelo significado das informações, eliminando duplicatas nos resultados sobrepostos e medindo recall, precisão, tempo de execução e custo financeiro. O protocolo também trata a verdade factual como algo que pode evoluir; um achado do agente sem correspondência pode ser um falso positivo, mas também pode ser uma vulnerabilidade real ausente do conjunto de referência.
Essa abordagem se aproxima de como as equipes de AppSec avaliam o valor de um teste de intrusão: vulnerabilidades válidas, impacto claro, remoção de duplicatas, severidade e suporte à remediação. Um benchmark que apenas pergunta se o agente atingiu um objetivo predefinido pode ignorar esses requisitos.
Uma das ideias mais úteis do artigo é a avaliação cumulativa. Execuções repetidas podem revelar vulnerabilidades que um único teste ignora, mas também podem acumular falsos positivos. Nos experimentos dos autores, o Strix-Sonnet quase dobrou o recall mantendo uma precisão comparável, enquanto o PentAGI-Sonnet perdeu precisão à medida que os falsos positivos se acumularam. Para o pentesting contínuo, a pergunta é se a execução repetida melhora a cobertura mais rapidamente do que aumenta o ruído.
A confiabilidade adiciona outra camada. Um estudo de 400 execuções testou quatro modelos 100 vezes cada um contra o mesmo honeypot fixo, um alvo controlado com serviços sabidamente vulneráveis. As taxas de exploração total variaram consideravelmente: o Gemini alcançou todos os três serviços em 85 das 100 execuções, o Claude em 61/100, o GPT-4o-mini em 56/100 e o qwen2.5-coder em 25/100. O estudo também apontou grande variação nas estratégias: o GPT-4o-mini gerou 98 estratégias de ataque exclusivas ao longo de 100 execuções, comparado com 69 do qwen e 48 do Gemini.
A confiabilidade não é uma característica exclusiva do modelo. Os resultados do Claude foram fortemente afetados por erros de sobrecarga no lado do provedor, que interromperam diversas ativações e alteraram o desempenho medido. Para agentes implementados, o comportamento da API, limites de taxa, timeouts, registro de logs e tratamento de repetições tornam-se parte do sistema de segurança que está sendo avaliado.
Uma única execução bem-sucedida não é um pentest confiável, e uma única execução mal-sucedida não é uma avaliação completa. Os agentes de pentesting baseados em IA são sistemas estocásticos; eles necessitam de medições repetidas, classificação de falhas, logs de execução, validação no nível das descobertas e curvas de custo. A pergunta correta não é se o agente consegue ter sucesso, mas com que frequência ele tem sucesso, o que ele deixa passar, o que ele inventa e quão caro é confiar nele.
O mercado se move na mesma direção
Essas questões de avaliação estão se tornando práticas porque o pentesting com IA já não é apenas um tema de pesquisa acadêmica. Anúncios de produtos e de projetos de código aberto usam hoje uma linguagem semelhante: testes autônomos, contexto de aplicação, prova de explorabilidade, trilhas de auditoria, remediação e retestes. Essas alegações são sinais de mercado, não evidências independentes de eficácia.
Exemplos recentes incluem o anúncio de um provedor de nuvem descrevendo testes de invasão autônomos sob demanda com validação de vulnerabilidades, etapas de reprodução e sugestões de remediação; um anúncio do mercado de AppSec posicionando testes ofensivos contínuos em torno de contexto da aplicação, orquestração de modelos, validação e controles de auditoria; um repositório de recursos de IA para pentests de código aberto focado na análise de código fonte, identificação de caminhos de ataque e prova por exploração; e o anúncio de um produto de pentesting com IA centrado no contexto de negócios, validação de explorações e testes que podem ser reexecutados.
A direção em comum é clara, mesmo sem aceitar as alegações dos fornecedores de forma cega: o pentesting por IA está sendo estruturado em torno da validação contínua e de fluxos de trabalho orientados a provas. Os compradores devem perguntar como os achados são validados, como os falsos positivos são controlados, como as execuções são registradas, de que forma a revisão humana é incorporada ao fluxo e como a remediação é confirmada.
O futuro provável não será um cenário no qual um pentester monolítico de IA substitua uma equipe de segurança inteira. A tendência aponta para fluxos de trabalho em camadas de segurança baseados em IA, em que planejadores, usuários de ferramentas, modelos especializados, validadores, logs, triagem, aprovações humanas e etapas de correção trabalham juntos. A autonomia, por si só, não torna esse fluxo de trabalho útil. O valor real vem de demonstrar achados, preservar contexto para revisão e ajudar as equipes a corrigir o que o sistema descobre.
Uma pergunta melhor para compradores e desenvolvedores
A pergunta de aquisição menos útil é se uma ferramenta "usa IA". A melhor pergunta é o que o sistema consegue demonstrar sob restrições reais.
Um fluxo de trabalho sério de pentesting com IA deve explicar quais evidências produz, como reproduz os achados e como separa a descoberta da exploração. Deve mostrar como escopo, credenciais, ferramentas e estado são controlados; como falsos positivos, duplicatas e sucessos alucinados são tratados; e o que acontece quando o modelo se recusa, falha, entra em loop, repete um passo ou inventa um identificador. Também deve deixar claro quais ações exigem aprovação humana e como os resultados se relacionam à remediação e ao retesting.
Para desenvolvedores, as mesmas perguntas se tornam requisitos de design. Sistemas agênticos de pentesting precisam de logs, camadas de validação, classificação de falhas, medições de execuções repetidas e visibilidade dos custos. Eles também precisam de limites: o modelo não deve ser responsável por cada decisão de planejamento, execução, memória e aprovação. Os sistemas mais maduros que emergem das pesquisas recentes não são apenas prompts envolvidos em ferramentas de segurança; são fluxos de trabalho projetados sob medida em torno de modelos probabilísticos.
Os agentes de pentesting com IA estão se tornando reais o suficiente para serem avaliados a sério. E eles também são inconsistentes o suficiente para que demonstrações simples, rankings e claims promocionais não bastem. O progresso nessa área deve ser medido por descobertas válidas, evidências reproduzíveis, autonomia controlada e resultados práticos de remediação.
Isso nos leva à próxima questão. Se as equipes de segurança começarem a confiar em sistemas baseados em agentes para pentests, remediação, revisão de código e red teaming de IA, como faremos para proteger esses próprios agentes? Governança, controle de acesso, segurança de modelos, logs, ética e divulgação responsável deixam de ser temas secundários; passam a fazer parte essencial da arquitetura de segurança. O próximo post analisará esse desafio de governança em mais detalhes: "Antes de confiar em agentes de segurança de IA, teste-os e governe-os".

Comece agora com o PTaaS da Fluid Attacks
Assine nossa newsletter
Mantenha-se atualizado sobre nossos próximos eventos e os últimos posts do blog, advisories e outros recursos interessantes.
Outros posts

























