Opiniões
GPT-5.4-Cyber, GPT-5.5 e a próxima fase da cibersegurança com IA


Redator e editor de conteúdo
13 min
No início de abril de 2026, a Anthropic deixou a indústria de cibersegurança em alerta com o Claude Mythos Preview e o Project Glasswing, um modelo e programa de parceiros que cobrimos em detalhe no nosso post anterior sobre Mythos e o futuro do AppSec. Cerca de uma semana depois, a OpenAI — por assim dizer — respondeu com o GPT-5.4-Cyber e um programa expandido Trusted Access for Cyber (TAC), e, em 23 de abril, lançou o GPT-5.5, um modelo de fronteira mais abrangente que a empresa descreve como superior ao GPT-5.4 em programação, uso de ferramentas, autonomia e cibersegurança.
O Mythos foi apresentado como um modelo tão capaz de encontrar e explorar vulnerabilidades que a Anthropic decidiu não disponibilizá-lo amplamente, pelo menos por enquanto. O GPT-5.4-Cyber da OpenAI foi enquadrado de forma diferente: como uma versão do GPT-5.4 permissiva para uso em cibersegurança, ajustada para trabalho defensivo e disponibilizada por meio de verificação de identidade em níveis. O GPT-5.5, por sua vez, não foi apresentado como um modelo apenas para cibersegurança, mas a OpenAI ainda dedicou parte do seu lançamento à cibersegurança e classificou o modelo como de capacidade "High" nesse domínio, no âmbito do seu Preparedness Framework.
O resultado é uma comparação útil, embora não simples. Mythos, GPT-5.4-Cyber e GPT-5.5 podem ser vistos — sobretudo os dois primeiros — como três respostas diferentes à mesma pergunta: como deve a IA de fronteira ser implementada quando se torna verdadeiramente útil tanto para defender quanto para atacar software?
O que a OpenAI realmente lançou com o GPT-5.4-Cyber
GPT-5.4-Cyber não é um modelo de fronteira separado. É uma versão do GPT-5.4 treinada para fluxos de trabalho defensivos de cibersegurança, e a mudança mais importante não é que o modelo "saiba de segurança"; é que o limite de recusa foi deliberadamente reduzido para trabalho legítimo de segurança. Defensores verificados devem encontrar menos atrito ao pedir ajuda em pesquisa de vulnerabilidades, programação defensiva, análise de malware, engenharia reversa e outras tarefas de duplo uso que os modelos de uso geral muitas vezes recusam.
A capacidade de maior destaque é a engenharia reversa de binários. Segundo a OpenAI, o GPT-5.4-Cyber pode apoiar fluxos de trabalho em que profissionais de segurança analisam software compilado para avaliar potencial de malware, vulnerabilidades e robustez de segurança sem precisar do código-fonte original. Isso é importante porque a análise de binários tradicionalmente exigiu conhecimento especializado escasso e semanas de trabalho manual; um modelo que possa ajudar um defensor a fazer triagem de executáveis, raciocinar sobre comportamento suspeito e mapear superfícies de ataque prováveis pode mudar materialmente a economia da análise de malware e da pesquisa de vulnerabilidades, desde que os resultados sejam validados cuidadosamente.
O acesso é limitado aos níveis mais altos do programa TAC da OpenAI, que depende de verificação de identidade, sinais de confiança empresarial e autenticação adicional para utilizadores que procuram capacidades mais permissivas. Defensores individuais podem verificar a sua identidade através de um portal dedicado, o que lhes dá menos atrito em torno das salvaguardas para modelos existentes. Equipes empresariais podem solicitar acesso por meio do seu representante da OpenAI para toda a organização de segurança. Usuários que procuram capacidades mais permissivas, incluindo o próprio GPT-5.4-Cyber, devem completar a autenticação adicional e podem ser obrigados a renunciar à Zero-Data Retention para que a OpenAI possa monitorizar como o modelo está a ser usado, particularmente quando é acedido através de plataformas de terceiros.
Os princípios declarados da OpenAI são acesso democratizado, implementação iterativa e resiliência do ecossistema: em vez de ter um pequeno comité a decidir quem é "confiável o suficiente" para defender os seus sistemas, a empresa quer colocar ferramentas cada vez mais capazes nas mãos de defensores verificados enquanto aprende com o uso real, fortalece salvaguardas contra jailbreaks e uso adversarial indevido, e apoia o ecossistema de segurança mais amplo através de subsídios, iniciativas de código aberto e produtos como Codex Security. A OpenAI diz que o Codex Security contribuiu para mais de 3.000 vulnerabilidades críticas e de alta severidade corrigidas, e que o seu programa Codex for Open Source chegou a mais de 1.000 projetos de código aberto com verificação de segurança gratuita.
Uma ressalva importante é que a OpenAI não publicou um cartão de benchmark público detalhado para o próprio GPT-5.4-Cyber. O registo público é atualmente mais forte sobre o que o modelo pretende fazer, como o acesso é governado e como se enquadra na estratégia cibernética mais ampla da OpenAI do que sobre o seu desempenho em tarefas independentes de descoberta de vulnerabilidades. Isso não torna o modelo insignificante, mas significa que as comparações diretas com o Mythos devem ser lidas com cautela.
GPT-5.5: não "GPT-5.5-Cyber", mas continua sendo muito relevante
O GPT-5.5 chegou nove dias após o anúncio do GPT-5.4-Cyber, apresentado como um modelo de fronteira geral para trabalho complexo em programação, pesquisa, análise de dados, criação de documentos, folhas de cálculo e uso de computadores. A OpenAI enfatiza que o GPT-5.5 consegue compreender mais cedo uma tarefa confusa e multietapas, usar ferramentas de forma mais eficaz, verificar o próprio trabalho e continuar através da ambiguidade com menos microgestão. Para a cibersegurança, essa combinação importa porque o trabalho real de segurança raramente é um único prompt; é uma sequência de leitura de código, formulação de hipóteses, execução de ferramentas, interpretação de falhas, proposta de correções e verificação de que o risco de fato mudou.
O lançamento também destaca melhorias de programação no Codex, incluindo desempenho mais forte em tarefas de engenharia de longo contexto, bem como em depuração, testes e validação. Testadores iniciais teriam descrito uma melhor capacidade de compreender a forma de um sistema, identificar onde uma correção pertence e antecipar como outras partes da base de código poderiam ser afetadas. Isso é diretamente relevante para a segurança de aplicações, porque muitos falhanços de remediação acontecem não no momento em que um bug é encontrado, mas quando a correção é incompleta, quebra a lógica circundante, ignora um sink ou source relacionado, ou falha em tratar a causa raiz. Um modelo que consegue manter mais contexto numa base de código mais ampla pode ser mais valioso como assistente de remediação do que apenas como detector.
Benchmarks e os limites da comparação
A tabela de avaliação publicada pela OpenAI coloca o GPT-5.5 em 81,8% no CyberGym, em comparação com 79,0% para o GPT-5.4 e 73,1% para o Claude Opus 4.7. O CyberGym inclui 1.507 vulnerabilidades históricas em 188 projetos de software e testa principalmente se agentes conseguem gerar testes de prova de conceito que reproduzam vulnerabilidades a partir de descrições e de bases de código. Os autores do benchmark enfatizam que isto é difícil porque os agentes têm de raciocinar sobre repositórios completos, localizar o código relevante e produzir artefactos de reprodução funcionais. Os próprios materiais da Anthropic, separadamente, afirmam que o Claude Mythos Preview atinge 83,1% em tarefas semelhantes de reprodução.
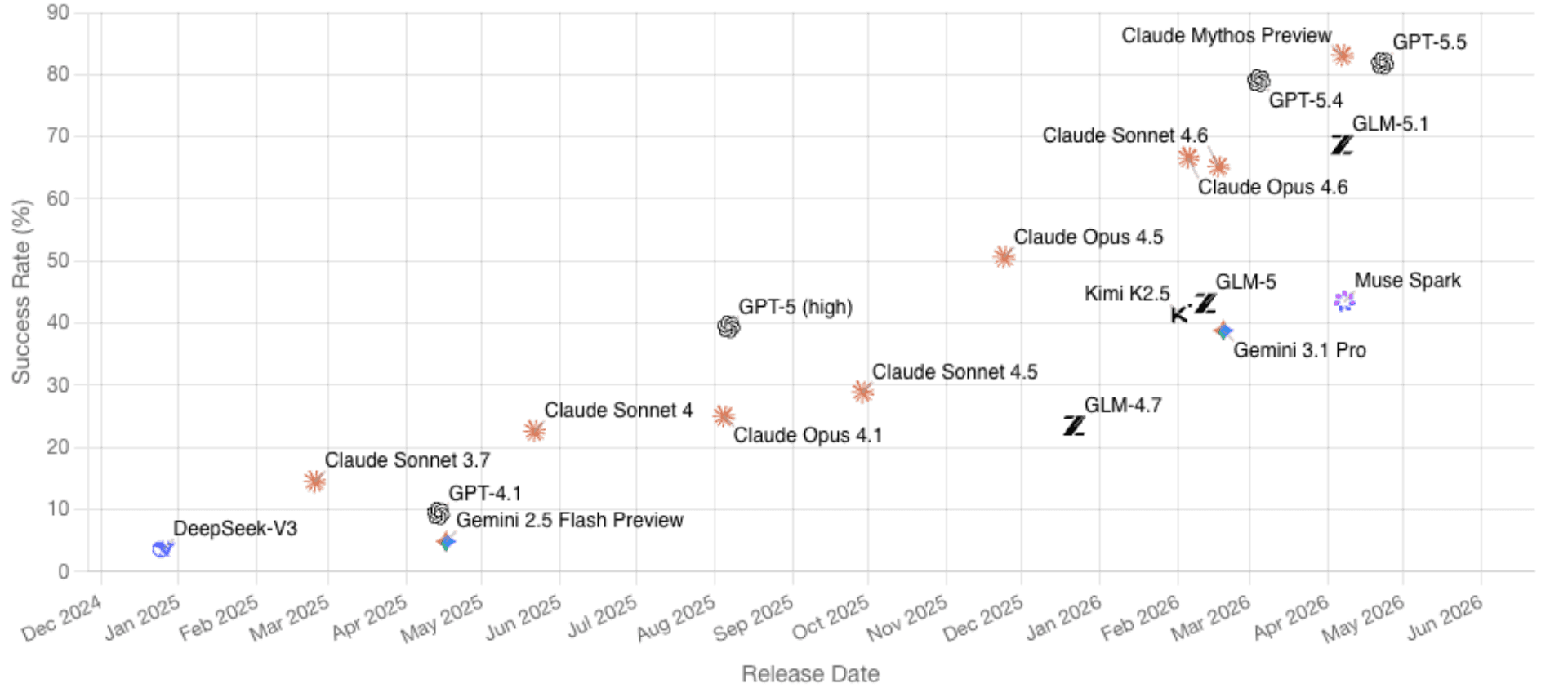
Benchmark do CyberGym (imagem obtida de cybergym.io em 30 de abril de 2026)
Estes números não devem ser sobreinterpretados. A tabela compara o GPT-5.5 com o GPT-5.4, não com o GPT-5.4-Cyber, pelo que a verdadeira posição da variante permissiva em cibersegurança continua pouco clara. O CyberGym é também um benchmark de reprodução de vulnerabilidades, não uma simulação completa de operações ofensivas contra alvos empresariais reforçados com defensores em tempo real, deteção em endpoints, controlos de identidade e resposta a incidentes. O comportamento em produção pode diferir ainda mais, uma vez que as avaliações da OpenAI foram executadas com alto esforço de raciocínio num ambiente de investigação.
O quadro torna-se mais vívido em avaliações mais longas e de múltiplas etapas que simulam cadeias de ataque completas. O UK AI Security Institute (UK AISI), por exemplo, testou o Mythos num cenário de 32 passos conhecido como o cenário TLO, em que o modelo completou toda a cadeia de ataque do início ao fim em três de dez tentativas e obteve uma média de 22 dos 32 passos em todas as tentativas. Nenhum modelo de IA avaliado anteriormente tinha conseguido concluir esse desafio específico de ponta a ponta.
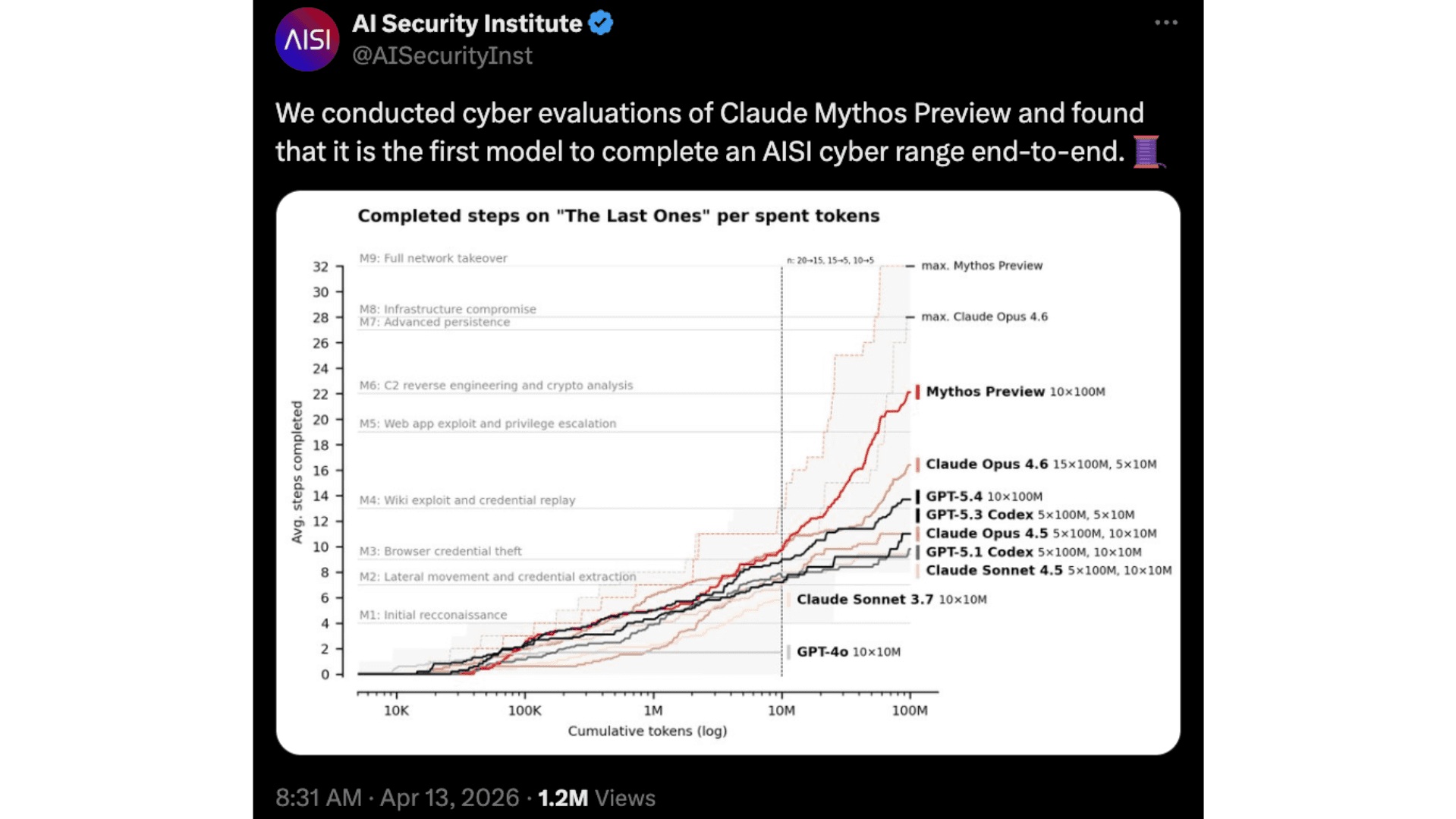
Publicação no X do UK AI Security Institute sobre a avaliação do Mythos no cenário TLO
O GPT-5.5 foi submetido a avaliações semelhantes de longo horizonte. O cartão de sistema da OpenAI relata uma taxa combinada de sucesso de 93,33% em certos cenários de cyber range, em comparação com 73,33% para o GPT-5.4 Thinking, atribuindo a maior taxa de sucesso à persistência na exploração. Avaliadores externos reforçaram o quadro: a Irregular reportou que o GPT-5.5 podia fornecer assistência significativa a operadores novatos ou moderadamente habilidosos e podia ajudar operadores altamente habilidosos em alguns casos, enquanto a UK AISI considerou o GPT-5.5 o modelo global mais forte que tinha testado em tarefas cibernéticas estreitas, embora dentro da margem de erro, e concluiu que o modelo resolveu um cyber range de rede corporativa de 32 passos de ponta a ponta numa de dez tentativas.
Capacidade elevada, mas abaixo de crítica
Segundo o Preparedness Framework da OpenAI, tanto o GPT-5.4-Cyber quanto o GPT-5.5 são classificados como modelos com capacidade de cibersegurança "High", mantendo-se abaixo do limiar "Critical". Um modelo com capacidade elevada pode automatizar operações cibernéticas de ponta a ponta contra alvos razoavelmente reforçados ou remover significativamente gargalos na descoberta de vulnerabilidades operacionalmente relevantes. Um modelo com capacidade crítica seria capaz de identificar e desenvolver exploits funcionais de zero-day em muitos sistemas críticos reais reforçados sem intervenção humana, ou executar novas estratégias de ciberataque de ponta a ponta contra alvos reforçados dadas apenas uma meta de alto nível.
A OpenAI afirma que o GPT-5.5 foi testado contra projetos de software amplamente implantados e reforçados usando computação elevada em tempo de teste e oráculos verificadores e que não produziu exploits funcionais de severidade crítica nas configurações padrão testadas. A empresa indicou que, se um modelo futuro atingisse o limiar crítico, o desenvolvimento adicional seria pausado até que salvaguardas mais fortes pudessem ser implementadas. (E o Mythos? Fique atento.)
A resposta de segurança da OpenAI para o GPT-5.5 também é mais rigorosa do que para modelos gerais anteriores, com controlos mais apertados em torno de atividade de maior risco, pedidos cibernéticos sensíveis e uso indevido repetido, enquanto o acesso de confiança é usado para reduzir recusas desnecessárias para defensores verificados. Na prática, a OpenAI está a dividir a experiência: o acesso amplo ao GPT-5.5 vem com classificadores e monitorização mais fortes; usuários cibernéticos de confiança podem solicitar menos restrições para trabalho defensivo legítimo.
Comparação com Claude Mythos e Project Glasswing
A formulação da Anthropic é mais dramática. Como expressámos no nosso post anterior no blogue (que o convidamos a ler para mais detalhes), a empresa descreve o Claude Mythos Preview como um modelo de linguagem de uso geral especialmente capaz em tarefas de segurança informática, e afirma que o Mythos consegue identificar e explorar vulnerabilidades de zero-day em todos os principais sistemas operativos e browsers da web quando orientado para isso. Supostamente, o Mythos também consegue fazer engenharia reversa de exploits em software de código fechado e transformar vulnerabilidades conhecidas, mas ainda não amplamente corrigidas, em exploits funcionais, com uma taxa de sucesso reportada acima de 72% em certas tarefas de geração de exploits.
O Project Glasswing é a resposta da Anthropic ao problema de implementação. Em vez de tornar o Mythos amplamente disponível, a Anthropic está a dar a parceiros selecionados, incluindo Google, Microsoft e NVIDIA, acesso para identificar e corrigir vulnerabilidades em sistemas fundamentais que representam uma grande parte da superfície de ataque compartilhada. O trabalho abrange deteção local de vulnerabilidades, testes black-box de binários, segurança de endpoint e testes de penetração. A Anthropic comprometeu 100 milhões de dólares em créditos de uso de modelo para o Glasswing e participantes relacionados, juntamente com doações a organizações de segurança de código aberto, e comprometeu-se a relatar publicamente o que aprendeu no prazo de 90 dias, quando a divulgação o permitir.
O contraste com a OpenAI é, portanto, em parte técnico e em parte político. O Mythos é apresentado como um modelo de fronteira inovador cuja capacidade cibernética autónoma requer um lançamento muito restrito. O GPT-5.4-Cyber é apresentado como uma variante especializada e ciberpermissiva de um modelo existente, posicionada sob um sistema de verificação mais amplo. O GPT-5.5 é um modelo geral cujas capacidades cibernéticas são fortes o suficiente para exigir salvaguardas reforçadas, mas, segundo a OpenAI, continua abaixo do limiar crítico. Estas diferenças importam porque o comentário público frequentemente trata o GPT-5.4-Cyber e o Mythos como equivalentes diretos. Os dois são semelhantes por serem controlados, de duplo uso e orientados para a defesa; diferem nos perfis de capacidade declarados, nas bases de evidência e nas filosofias de acesso.
A Anthropic publicou exemplos mais explícitos de descoberta de zero-days e geração de exploits, enquanto a OpenAI publicou mais detalhes sobre a sua estrutura de acesso e avaliações cibernéticas gerais. Nos benchmarks, a Anthropic diz que o Mythos supera substancialmente o Opus 4.6, e a OpenAI reporta que o GPT-5.5 supera o GPT-5.4 e o Opus 4.7 no CyberGym, mas o Opus 4.7 não é o Mythos, e o GPT-5.4 não é necessariamente o GPT-5.4-Cyber. Qualquer tabela de classificação limpa seria enganosa a menos que fossem usadas as mesmas tarefas, ambientes de ferramentas, definições de recusa e padrões de verificação.
Os dois modelos de acesso também incorporam apostas distintas. A aposta da Anthropic é que certas capacidades devem ser mantidas dentro de um consórcio restrito até que as salvaguardas melhorem; a da OpenAI é que a população defensora precisa de acesso mais amplo e verificado porque os atacantes não vão esperar. Um lançamento restrito reduz o risco de distribuição, mas pode criar um ecossistema de segurança de dois níveis, no qual apenas as maiores organizações recebem as ferramentas mais fortes; um modelo de acesso confiável mais amplo ajuda mais defensores, mas requer verificação de identidade robusta, monitorização, resposta a abusos e governança contínua. A questão mais difícil não é qual empresa soa mais responsável; é se alguma das abordagens consegue escalar sem criar pontos cegos, dependências ou vantagens acidentais para os atacantes.
Confiança sob pressão: o incidente do fornecedor do Mythos
A questão da governança tornou-se mais aguda depois da Bloomberg ter reportado que usuários não autorizados tinham acedido ao Mythos através de um ambiente de fornecedor de terceiros, com o acesso alegadamente a coincidir com o dia em que a Anthropic anunciou pela primeira vez os seus planos de testes limitados. A Anthropic confirmou que estava a investigar o relatório. O incidente, considerado em conjunto com problemas anteriores como falhas no Model Context Protocol (MCP) e uma fuga separada causada por erro humano que expôs cerca de 500.000 linhas de material de source-map do Claude Code no npm, ilustra um desafio central para qualquer laboratório que construa IA com capacidades cibernéticas: controlo de acesso, segurança de fornecedores e monitorização operacional tornam-se parte do caso de segurança, e não meros detalhes administrativos.
Dinâmica de mercado: receitas, "criti-hype" e o setor financeiro
A competição entre Anthropic e OpenAI não é apenas técnica; é também uma disputa pelo domínio de mercado e pela confiança dos investidores. A Anthropic, que alegadamente se prepara para uma oferta pública inicial, viu as suas receitas anualizadas atingirem 30 mil milhões de dólares, ultrapassando a cifra mais recentemente divulgada para a OpenAI. Alguns observadores da indústria apelidaram a estratégia de descrever um modelo como "demasiado perigoso para ser lançado" de "criti-hype", argumentando que alertar em voz alta sobre os perigos extremos de uma tecnologia pode simultaneamente inflacionar o seu valor percebido entre os investidores. Quer se aceite ou não essa formulação, ela explica por que cada divulgação do Mythos funciona ao mesmo tempo como mensagem de segurança e declaração de marca.
A OpenAI seguiu uma direção diferente ao ancorar o seu programa cibernético em parcerias empresariais. Grandes instituições financeiras, incluindo Bank of America, BlackRock, BNY, Citi, Goldman Sachs, JPMorgan Chase e Morgan Stanley, aderiram para apoiar ou participar no programa Trusted Access for Cyber. Estas instituições gerem sistemas legados vastos, difíceis de substituir e caros de proteger, tornando-se adotantes naturais de defesa assistida por IA em escala.
A lacuna de ação entre as empresas
Talvez a realização mais importante de 2026 seja a deteção de vulnerabilidades estar a caminho de se tornar um bem comum; está cada vez mais barata, abundante e automatizada. Como argumentou Rafael Álvarez, cofundador da Fluid Attacks, o problema principal na segurança de aplicações raramente é a descoberta; é a disciplina. As empresas muitas vezes sabem exatamente o que está quebrado, mas falham em corrigi-lo devido a restrições de recursos, priorização fraca ou falta de contexto.
A avalanche de relatórios de vulnerabilidades gerados por IA acende nova pressão sobre os mantenedores de software. Mesmo uma descoberta de alta qualidade requer tempo humano para validar, testar e integrar, e a capacidade dos projetos de código aberto de absorver um grande volume de descobertas não cresce ao mesmo ritmo que a capacidade da IA de revelá-las. A janela entre a divulgação e a exploração continua a diminuir, tornando os calendários tradicionais de correção obsoletos quando um adversário pode passar da descoberta à exploração em minutos.
O papel do engenheiro de segurança está a mudar em resposta. Os engenheiros já não são os principais "encontradores" de vulnerabilidades; estão a tornar-se os decisores que orquestram agentes de IA, validam os seus resultados e tomam decisões de alto impacto sobre a priorização de riscos. As plataformas de segurança mais valiosas neste ambiente serão aquelas que conseguem transformar descobertas em decisões acionáveis, coordenar a remediação em escala em ambientes complexos, fornecer verificação contínua de que uma correção realmente reduziu a exposição e integrar-se de forma limpa aos fluxos de trabalho reais de desenvolvimento e produção.
O que os defensores devem aprender com esses lançamentos
O UK National Cyber Security Centre tem argumentado que a IA de fronteira já está a mudar o custo, a velocidade e a escala das operações cibernéticas tanto para atacantes como para defensores, incluindo tarefas como escrita de código de exploits, compreensão de arquitetura de sistemas e uso de ferramentas. O NCSC também argumenta que os defensores mantêm vantagens estruturais se se prepararem adequadamente, pois controlam os seus próprios sistemas, registos, pipelines de compilação, arquitetura de identidade e processos de remediação. Essa vantagem desaparece quando as organizações tratam a IA como um scanner aparafusado a um fluxo de trabalho de segurança já fragmentado.
Para programas de segurança de aplicações, a lição prática é construir um ciclo fechado em torno das descobertas assistidas por IA. Um fluxo de trabalho útil liga descoberta, evidência, contexto de negócio, explorabilidade, propriedade, orientação de remediação, reteste e auditabilidade. Normaliza descobertas de múltiplas fontes em vez de criar mais um silo e preserva espaço para revisão humana onde o custo de estar confiantemente errado é elevado. Também acompanha o desempenho do modelo em termos específicos de segurança: falsos positivos, falsos negativos, reprodutibilidade, qualidade da correção, tempo de validação, tempo de remediação, taxa de regressão e integração com os fluxos de trabalho existentes dos programadores.
A pergunta operacional para um CISO é, portanto, não apenas se o GPT-5.5 pontua mais alto do que o GPT-5.4 no CyberGym, ou se o Mythos é mais forte na descoberta de zero-days, mas se uma equipa de segurança consegue usar estes sistemas sem sobrecarregar mantenedores, inundar os processos de CVE, empurrar patches inseguros ou conceder confiança excessiva a saídas de IA não verificadas. Um modelo que acelera a descoberta sem reforçar a disciplina de remediação simplesmente cria uma fila maior com uma linguagem mais impressionante à volta.
A mesma lógica aplica-se a infraestruturas críticas, serviços financeiros, saúde, telecomunicações e tecnologia operacional, onde o código legado, dependências frágeis e janelas longas de manutenção já limitam a rapidez com que as correções podem ser lançadas; se a IA continuar a tornar a descoberta mais barata enquanto a correção permanece limitada, a diferença entre risco conhecido e risco resolvido torna-se uma medida central da resiliência organizacional.
Recomendações estratégicas para a liderança
Para executivos e líderes de segurança que tentam transformar estes anúncios em ação, surgem algumas prioridades:
Adotar o acesso por níveis desde cedo. As equipas de segurança devem iniciar agora o processo de candidatura ao Trusted Access for Cyber, para que tenham acesso verificado a modelos como o GPT-5.4-Cyber quando necessário, em vez de recorrerem a ele durante uma crise.
Usar a IA como assistente de triagem, não como oráculo. Aplique os modelos mais fortes a casos de uso específicos e restritos, como engenharia reversa de binários para análise de malware ou revisão de código com restrições de política dentro de pipelines CI/CD, onde os resultados possam ser verificados com controles determinísticos.
Investir no ciclo de remediação, não apenas na deteção. Estabeleça um sistema de ciclo fechado em que a propriedade seja atribuída, a remediação seja acompanhada, as correções sejam rigorosamente retestadas e a redução da exposição ao risco seja mensurável.
Planejar auditoria e supervisão. À medida que as descobertas automatizadas se tornam mais prevalentes, regimes regulatórios como o AI Act da UE exigirão supervisão humana documentada sobre como estes sistemas são usados dentro da função de segurança.
O valor muda de encontrar para decidir
O GPT-5.4-Cyber e o GPT-5.5 mostram que a OpenAI está a avançar numa estratégia cibernética em camadas: modelos gerais mais capazes, salvaguardas mais fortes para acesso amplo e fluxos de trabalho mais permissivos para defensores verificados. O Claude Mythos mostra que a Anthropic está disposta a apresentar capacidades cibernéticas de fronteira como demasiado poderosas para um lançamento normal, canalizando-as através de um programa de parceiros controlado. Estas estratégias diferem de formas importantes, mas apontam para a mesma estrutura de mercado: as capacidades de IA mais fortes serão cada vez mais distribuídas por meio de níveis de confiança, requisitos de segurança e acesso monitorado, em vez de simples disponibilidade pública.
Para fornecedores de segurança e equipes empresariais, o diferenciador mudará em conformidade. A deteção continuará a ser importante, mas perderá valor estratégico se não for acompanhada de validação, priorização e remediação verificada. Os programas de segurança mais valiosos serão aqueles que conseguem transformar um volume abundante de descobertas geradas por máquinas em decisões fiáveis: quais os problemas que importam, quem é o proprietário, como devem ser corrigidos, se a correção é segura e se o risco subjacente realmente desapareceu. Os agentes de IA podem ajudar em toda essa cadeia, mas não eliminam a necessidade de responsabilização, evidência e julgamento humano.
A questão para as organizações, portanto, não é se devem esperar pelo modelo perfeito, mas se estão a preparar a abordagem operacional necessária para usar qualquer um destes sistemas de forma responsável. Isso significa inventariar software e dependências, reduzir a dívida de vulnerabilidades por resolver, melhorar a propriedade e os SLAs de remediação, validar saídas de IA com ferramentas determinísticas e revisão de especialistas, e manter evidências de que as correções reduzem a exposição.
O valor de segurança não é medido pelo número de descobertas geradas; é medido pela quantidade de risco reduzido. À medida que a IA de fronteira acelera a descoberta e a torna mais amplamente disponível, as organizações que saírem na frente serão aquelas que conseguirem absorver o ritmo sem perder o controle.
Se acha que a sua empresa precisa de ajuda para implementar estratégias que abordem estas transformações na cibersegurança com IA, não hesite em contactar a Fluid Attacks.

Comece agora com a solução ASPM da Fluid Attacks
Assine nossa newsletter
Mantenha-se atualizado sobre nossos próximos eventos e os últimos posts do blog, advisories e outros recursos interessantes.
Outros posts
























