Filosofía
Más rápido que el adversario: reduciendo la ventana de exposición desde el código hasta el tiempo de ejecución


Escritor y editor
11 min
En El arte de la guerra, Sun Tzu escribió que "la rapidez es la esencia de la guerra", instando a los comandantes a aprovechar la falta de preparación del enemigo y atacar donde no se hubieran tomado precauciones. Veinticinco siglos después, esa frase parece parte de un manual de campaña para los ciberataques modernos. Durante la mayor parte de la historia de Internet, los defensores tenían el tiempo de su lado, pero ya no es así.
El intervalo entre la divulgación y la explotación de las vulnerabilidades, lo que los investigadores llaman tiempo de explotación (time-to-exploit, TTE), se ha ido reduciendo durante años, y en 2025 prácticamente llegó a cero. Según el Zero Day Clock, que realiza un seguimiento del TTE en más de 83.000 vulnerabilidades, la mediana cayó de 2,1 años en 2018 a 2,2 meses en 2021, luego a 5,3 días en 2023 y a solo 12 horas en 2024. Para entonces, la falla típica se explotaba en el momento en que se hacía pública, a veces antes de que los defensores supieran que existía.
Ese colapso cambia la pregunta que todo programa de AppSec debe responder. El instinto es remediar las vulnerabilidades lo más rápido posible, pero la velocidad por sí sola es una carrera que ya no se puede ganar. El mejor objetivo, y el que trata este post, es reducir tu propia ventana de exposición desde el código hasta el tiempo de ejecución (runtime): previniendo fallas antes de que se envíen y bloqueando las explotaciones que logran pasar en el tiempo de ejecución, para que la velocidad del atacante ya no decida si sufres una brecha de seguridad.
La ventana se ha cerrado
Durante años, el manual del defensor fue una apuesta razonable: encontrar la falla, esperar un parche o una corrección y programar la actualización o remediación. La IA ha roto esa apuesta. Ahora, un modelo puede leer un parche de seguridad, deducir la falla que corrige y producir un exploit funcional en cuestión de minutos. La debilidad subyacente es más antigua que la IA actual: hace dos décadas, el investigador de seguridad Halvar Flake creó BinDiff, una herramienta que compara un programa antes y después de una corrección para revelar la vulnerabilidad exacta que fue remediada. En la práctica, cada corrección funciona como un mapa para atacar a cualquiera que aún no la haya aplicado. La IA simplemente lee ese mapa en minutos, a gran escala.
Esta misma aceleración está transformando el lado del descubrimiento, donde el descubrimiento de vulnerabilidades impulsado por IA está sacando a la luz fallas en software de uso común más rápido de lo que los mantenedores pueden responder. Al juntar ambas tendencias, la brecha resulta abrumadora. Hoy en día, un exploit suele aparecer pocas horas después de que se conoce una falla, mientras que el despliegue completo de un parche en un entorno real sigue tardando semanas. Durante casi todo ese tiempo de espera de semanas, excepto las primeras horas, ya circula un exploit funcional mientras la organización sigue sin tener una corrección implementada. La explotación y la remediación operan ahora en órdenes de magnitud diferentes: horas frente a semanas.
El tiempo de explotación se ha reducido casi a cero, por lo que cualquier estrategia basada en ganar una carrera de parches ya está perdida.
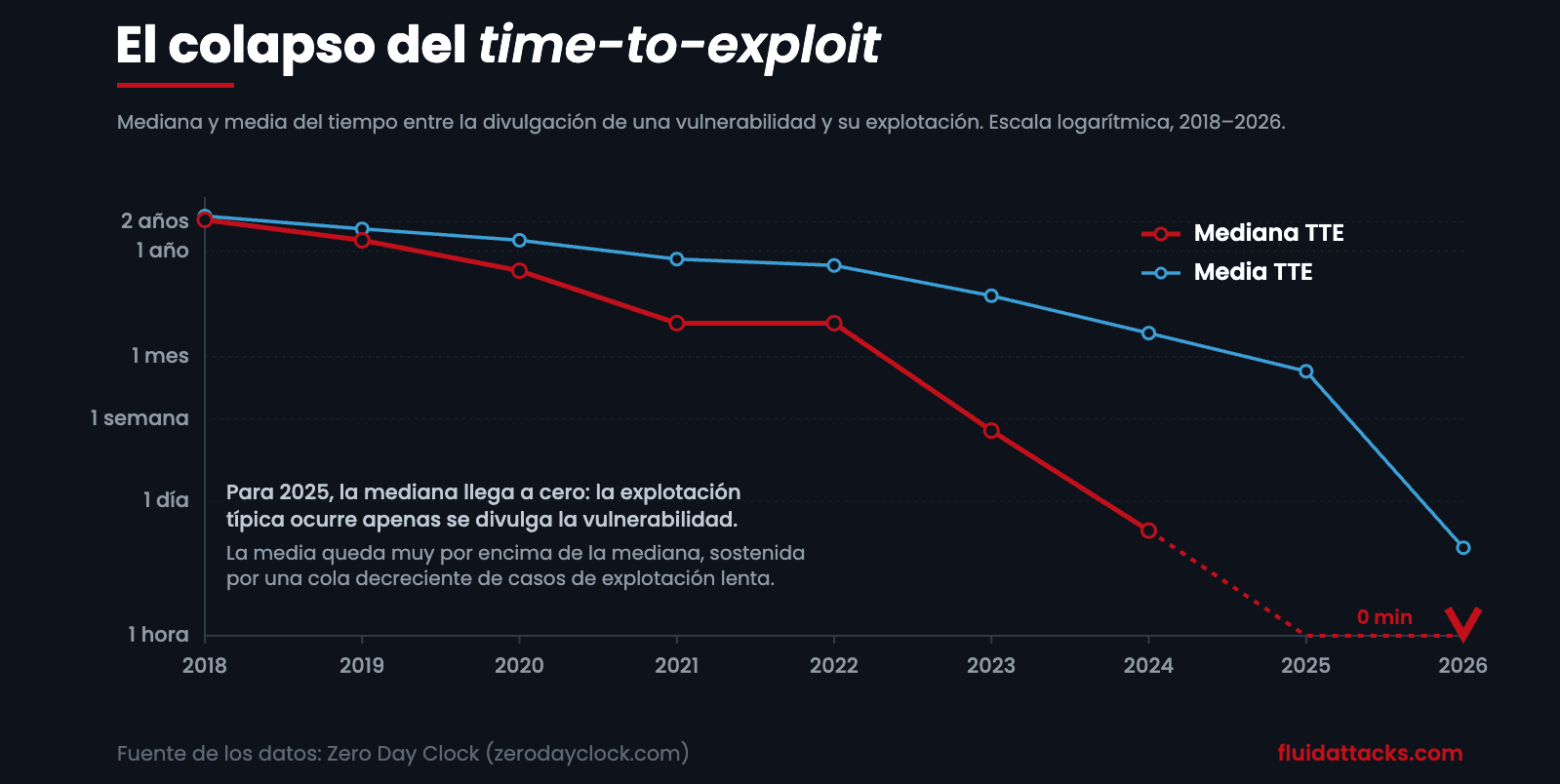
El colapso de la mediana y de la media del tiempo de explotación, de 2018 a 2026. Fuente de datos: Zero Day Clock (al 19 de junio de 2026).
Dos ventanas, una carrera
Imagina dos ventanas de tiempo. La primera es la ventana de explotación: el tiempo que un adversario necesita para convertir una vulnerabilidad en un ataque funcional. La segunda es la ventana de exposición: el tiempo que necesitas para pasar de detectar una falla en tu propio entorno a cerrarla realmente. No controlas la primera, pero controlas, en gran medida, la segunda. El hecho de sufrir o no una brecha de seguridad a menudo se reduce a una comparación directa entre ambas.
Para las vulnerabilidades conocidas (fallas que han sido divulgadas públicamente, que suelen tener un identificador CVE y una corrección disponible), la contienda parece ganable sobre el papel. Se aplica la corrección y la ventana se cierra. El problema es que la carrera de remediación tiene un límite mínimo por debajo del cual no se puede bajar. Probar, preparar y desplegar una corrección en un entorno real toma, en el mejor de los casos, varios días, y el Verizon Data Breach Investigations Report de 2026 reveló que el tiempo medio para solucionar una falla por completo aumentó a 43 días el año pasado, y las organizaciones aplicaron solo cerca de una cuarta parte de las correcciones del catálogo estadounidense de vulnerabilidades explotadas conocidas. Ese mismo informe calificó la explotación de vulnerabilidades como la forma más común en que los atacantes logran ingresar, superando por primera vez a las credenciales robadas, y los analistas de respuesta a incidentes de Mandiant llegaron al mismo veredicto, siendo la explotación el principal vector de acceso inicial por sexto año consecutivo.
Reducir esos 43 días a una sola semana sería un logro real, y aun así se perdería, porque la ventana de explotación es de apenas unas horas. Para una vulnerabilidad de día cero (zero-day), la situación es aún peor. Una zero-day es una falla que aún no es pública o no cuenta con una corrección disponible, por lo que los defensores han tenido cero días para prepararse. Sencillamente, no hay nada que aplicar. Esta es la trampa que se oculta tras el lema de "parchear más rápido": es una medida útil para los errores conocidos, pero está limitada por un suelo que se mide en días, y no sirve de nada ante la creciente proporción de ataques que llegan antes de que exista cualquier solución. Competir únicamente en velocidad de remediación equivale a intentar superar una ventana que no controlas.
El camino a seguir no consiste en abandonar la remediación, sino en ampliar lo que se considera cerrar la ventana. La reduces antes de que el código se envíe, previniendo las fallas de manera temprana, y de nuevo en producción, bloqueando los exploits en tiempo de ejecución, en lugar de confiar únicamente en una corrección más rápida una vez que la falla ya es pública. Remediar más rápido es algo que vale la pena hacer, pero esto por sí solo nunca podrá constituir toda la defensa.
Por qué "detectar y parchear ha muerto" es solo una verdad a medias
Un número cada vez mayor de proveedores de seguridad en tiempo de ejecución ha basado su propuesta en una afirmación contundente: el modelo de detectar y parchear ha muerto. Teniendo en cuenta todo lo que muestran las dos ventanas, no se equivocan al decirlo. Si la explotación llega en horas mientras sus correcciones tardan semanas en desplegarse, apoyarse en un ciclo de parches mensual como defensa principal es, como muestran los datos, algo más cercano al "teatro de la seguridad" que a una protección real: una rutina que parece responsable pero que ya no detiene los ataques. La conclusión honesta es que se necesita una forma de detener un exploit en producción, en el momento en que se ejecuta, sin esperar a que haya una solución disponible. Esa capacidad es real y fundamental.
El peligro reside en el siguiente paso que dan algunos: tratar el bloqueo en tiempo de ejecución como un sustituto de todo lo que ocurre antes de este. Esa es la lección equivocada por dos razones.
En primer lugar, un control en tiempo de ejecución es una última línea de defensa, no la única. Cualquier capa de detección presenta falsos negativos: fallas o ataques que debería haber capturado, pero no los capturó. Si el bloqueo en producción es lo único que se interpone entre un adversario y tus datos, entonces un solo fallo se convierte en una brecha sin nada detrás; habrás apostado toda la defensa a una sola muralla.
En segundo lugar, abandonar la prevención deja esa única muralla para contener una marea creciente. La IA está generando más código, y más código significa más vulnerabilidades que llegan a producción, incluso si la tasa por línea se mantiene estable. Si dejas de intentar reducir la cantidad de fallas que se envían, le estarás pidiendo a una sola capa en tiempo de ejecución que contenga una inundación en constante aumento, para siempre. Encontrar y solucionar los problemas antes es lo que evita que el agua suba en primer lugar.
También hay una trampa más silenciosa. El lema "detectar y parchear ha muerto" puede degenerar en "¿Entonces para qué molestarse en solucionar las cosas?", cuando, en realidad, muchas organizaciones ya conocen muchas más vulnerabilidades de las que remedian. Como argumentamos en un análisis reciente sobre quién es responsable de asegurar el software desarrollado por IA, la limitación suele ser la disciplina y la responsabilidad, no la detección. La defensa en tiempo de ejecución debe respaldar esa disciplina, no dar a los equipos una excusa para abandonarla. El eslogan tiene solo la mitad de razón: el ritmo de parcheo ya no es una defensa, pero la prevención no es obsoleta. La estrategia consiste en añadir una línea de defensa en tiempo de ejecución, no en derribar las que ya están al frente.
Qué significa realmente "detenerlo en tiempo de ejecución"
La capacidad que venden esos proveedores ya tiene nombre. Los analistas la llaman detección y respuesta en aplicaciones (ADR) y es el miembro más reciente de una familia que posiblemente ya conozcas. La detección y respuesta en endpoints (EDR) vigila la máquina. La detección y respuesta en la red (NDR) supervisa el tráfico. La detección y respuesta en la nube (CDR) vigila la cuenta de la nube. La ADR supervisa la propia aplicación mientras se ejecuta.
Esta última distinción es el punto clave, por lo que vale la pena precisar en qué se diferencia la ADR de las herramientas que la acompañan. Un firewall de aplicaciones web (WAF) vigila la puerta principal, inspeccionando el tráfico en el perímetro en busca de patrones maliciosos, pero no tiene visibilidad de lo que ocurre dentro de la aplicación y suele ser evadido. La EDR y la CDR observan la máquina o la nube que rodea a la aplicación, lo que suele significar que detectan las consecuencias de un exploit (por ejemplo, el inicio de un proceso sospechoso) en lugar del exploit en sí. El pariente antiguo más cercano es la autoprotección de aplicaciones en tiempo de ejecución (RASP), que sí intentaba vigilar desde el interior de la aplicación, pero requería que los desarrolladores instrumentaran su propio código, un paso invasivo que resultó difícil de adoptar a escala, razón por la cual quedan pocos productos RASP.
La estrategia de la ADR consiste en obtener esa visión desde el interior de la aplicación, hasta el nivel de las funciones que se están ejecutando, sin recurrir a esa instrumentación invasiva. Muchas implementaciones observan el comportamiento desde el nivel del sistema operativo, por lo que pueden saber qué está haciendo la aplicación en tiempo real sin tocar el código fuente y decidir si una acción determinada es legítima o el inicio de un ataque.
Un caso práctico hace que esto sea tangible. Log4Shell fue la falla de 2021 en Log4j, una librería de registro utilizada en innumerables aplicaciones Java, que permitía a los atacantes ejecutar código arbitrario simplemente registrando una cadena maliciosa. El mecanismo abusaba de una función llamada JNDI que normalmente realiza búsquedas de directorio inofensivas a través de la red. Una defensa en tiempo de ejecución no intenta reconocer la cadena maliciosa, que puede estar ofuscada indefinidamente. En su lugar, observa el comportamiento: en el momento en que el componente JNDI deja de realizar búsquedas legítimas y comienza a buscar y ejecutar código remoto, esa acción específica se bloquea, mientras que el resto de la librería de registro sigue funcionando. No se requiere ningún parche porque la defensa se dirige al comportamiento del exploit en lugar de a una firma conocida, lo cual explica también por qué este enfoque puede detener un verdadero zero-day que nunca antes se ha visto.
En lo que respecta a las dos ventanas, este es el extremo de producción de su ventana de exposición: la última línea de defensa contra aquello que la prevención no detuvo antes de que se enviara el código.
La IA reconfigura ambos lados de la línea
Comenzamos hablando de un colapso, y la IA es su motor. Las mismas herramientas que ayudan a los defensores están —en manos de personas malintencionadas— descubriendo y convirtiendo fallas en armas a un ritmo que ningún equipo humano puede igualar, ya sea en forma de agentes de pentesting con IA o de sistemas de frontera como Claude Mythos de Anthropic. Ese es el lado ofensivo de la carrera y la razón por la que la ventana de explotación sigue reduciéndose. Pero la IA también hace algo más sutil. No solo acelera los ataques contra tu software, sino que también se convierte en una nueva pieza de software que debes defender.
Las organizaciones están desplegando agentes de IA que leen datos, invocan herramientas, ejecutan código y toman medidas por sí mismos. Esto añade una nueva superficie de ataque que no existía hace unos años, y tiene dos capas. Los propios modelos pueden ser manipulados (el campo del aprendizaje automático adversarial), donde entradas diseñadas específicamente hacen que un modelo se comporte de forma incorrecta. Y los sistemas de agentes construidos sobre ellos introducen una capa operativa: en el fondo, cada herramienta a la que llama un agente es una llamada de función, y el tejido conectivo que expone esas herramientas es cada vez más el Model Context Protocol (MCP), un estándar abierto para conectar modelos a sistemas externos.
La amenaza principal en la capa de agentes es la inyección indirecta de prompts, en la que un atacante introduce instrucciones maliciosas en el contenido que el agente va a leer (una página web, un documento o un ticket de soporte) y el agente las sigue como si procedieran de su operador. Cuando ese agente puede ejecutar código o llamar a herramientas sensibles, una inyección exitosa no solo produce una frase errónea. Puede desencadenar acciones reales, llegando incluso a la ejecución de código elegido por el atacante. Las conexiones añaden su propio riesgo, ya que los servidores MCP y sus configuraciones se convierten en componentes susceptibles de abuso, al igual que cualquier otro.
He aquí por qué esto encaja en la misma conversación que la defensa en tiempo de ejecución. Una vez que un agente actúa, su comportamiento es, en última instancia, código que se ejecuta en un sistema, lo que significa que una defensa en tiempo de ejecución plantea la misma pregunta que el ejemplo de Log4Shell: ¿Esta función está haciendo lo que se supone que debe hacer, o algo la ha secuestrado para ejecutar un exploit? Una inyección de prompts que termina en la ejecución de código malicioso se puede detectar de la misma manera que se detecta una llamada JNDI sospechosa. Y con la misma claridad, esta nueva superficie debe ser analizada antes de que se despliegue, no solo vigilada después de que lo haga, lo que sitúa a la IA plenamente dentro del modelo que combina la prevención temprana (shift left) y el tiempo de ejecución hacia el que nos dirigimos.
La IA amplía la carrera en el aspecto ofensivo y añade un nuevo objetivo a defender, pero, dado que las acciones de un agente se traducen en código que se ejecuta, la pregunta en tiempo de ejecución nunca cambia: ¿es este comportamiento legítimo o el inicio de un ataque?
La respuesta está en todo el ciclo de vida, no en una sola etapa
Al juntar todas las piezas, la estrategia deja de ser una elección entre anticipar la seguridad y defender en tiempo de ejecución. Son ambas cosas, apuntando al mismo objetivo: una ventana de exposición más corta. Se dividen el trabajo. A la izquierda se identifican y corrigen las vulnerabilidades antes de que se envíen, por lo que para estas la ventana nunca llega a abrirse. En producción, se detectan, se bloquean y se responde a los exploits que logran pasar, cerrando la ventana a las fallas que se pasaron por alto en la prevención, incluidas aquellas que no tienen parche aplicable. Ninguna de las dos opciones por sí sola es suficiente: la prevención evita que las ventanas se abran, y el tiempo de ejecución cierra las que logran abrirse.
Aquí es también donde la detección deja de ser la parte difícil. Como hemos argumentado anteriormente, la IA está haciendo que el descubrimiento de vulnerabilidades sea abundante y barato, lo que significa que el factor diferenciador ya no es cuántos problemas puedes detectar, sino con qué rapidez puedes actuar sobre ellos: priorizando lo que realmente conlleva un riesgo, remediándolo y verificando que la corrección efectivamente redujo la exposición al riesgo. Ese circuito cerrado, y no el volumen bruto de detección, es lo que mueve tu ventana de exposición.
Este es el modelo hacia el que Fluid Attacks ha apuntado durante años: ya combinamos herramientas automatizadas, IA y pentesters humanos para encontrar y ayudar a remediar vulnerabilidades a lo largo del ciclo de vida del software, con una única plataforma para priorizarlas y darles seguimiento hasta su cierre. Extender esa misma filosofía al tiempo de ejecución, para que la prevención y la defensa en producción compartan una única imagen continua del riesgo, es el paso natural y la dirección hacia la que se dirige el AppSec en su conjunto.
Conoce tu terreno
La frase más citada de Sun Tzu es también la más práctica: conoce al enemigo y conócete a ti mismo, y no tendrás por qué temer ni a cien batallas. Hemos dedicado este post a la primera mitad: el adversario y la velocidad del ataque. La segunda mitad, conocerse a sí mismo, es donde la mayoría de los programas pierden silenciosamente. No puedes acortar la ventana de exposición de una aplicación que olvidaste que estabas ejecutando, una dependencia que no sabías que habías desplegado o un servicio del que nadie se hace responsable. Permanecen expuestos tanto si los vigilas como si no.
Sun Tzu era igual de insistente sobre el terreno: un comandante que no conoce el territorio, sus desfiladeros, pantanos y terrenos elevados, no puede mover un ejército a través de él con confianza. En el software, tu terreno es el inventario completo y actual de lo que realmente ejecutas: aplicaciones, APIs, componentes y el código abierto y el de terceros que contienen. Sin ese mapa, la prevención no tiene a dónde apuntar y la defensa en tiempo de ejecución presenta puntos ciegos por defecto. Con él, puedes ver dónde se concentra el riesgo y actuar primero, lo cual es precisamente la ventaja que se supone que aporta la velocidad.
Por ello, un inventario confiable no es un elemento opcional o secundario en un programa de seguridad. Es el terreno sobre el que se corre toda la carrera. No puedes defender, priorizar o superar a un adversario en un terreno que no has mapeado, lo que hace que saber qué ejecutas sea la condición previa para cualquier otro movimiento.
Gana la ventana, no el parche
No hay línea de meta en esta carrera. La ventana de explotación seguirá reduciéndose a medida que la IA sea más barata y rápida, y ningún control individual, por bueno que sea, la cerrará de forma permanente. Esto no es motivo para desesperarse. Es una razón para cambiar la forma en que medimos el éxito. Remediar más rápido te seguirá permitiendo ganar carreras individuales, pero no puede ser la base: un exploit puede existir a las pocas horas de que se conozca una falla, a veces incluso antes, y una zero-day no deja margen para aplicar nada a tiempo. Por lo tanto, deja de medir el éxito en función de la rapidez con la que parcheas o remedias, y empieza a medir con qué frecuencia un atacante encuentra algo explotable en producción. Eso, y no la velocidad de remediación, es lo que decide si sufres una brecha de seguridad.
Mantenerse a la vanguardia significa rechazar la falsa opción. Prevén lo que sea posible en el lado izquierdo, para que menos fallas lleguen a producción. Defiende en tiempo de ejecución, para que el exploit que logre pasar, o la zero-day sin parche, sea detenido mientras se ejecuta. Y mapea tu terreno primero, para que cada movimiento tenga un objetivo claro. Este es el modelo integral, desde el código hasta el tiempo de ejecución, sobre el cual está construido Fluid Attacks y que continúa expandiéndose, porque ser más rápido que el adversario no es un eslogan; es todo nuestro trabajo.
Esa carrera ahora también pasa directamente por tus sistemas de IA. A medida que los agentes y las aplicaciones de modelos de lenguaje grandes asumen trabajo real, protegerlos se convierte en parte del mismo esfuerzo: proteger tu IA y las aplicaciones de LLM y de IA generativa que estás llevando a producción. Habla con nosotros para acortar tu ventana de exposición, desde el código hasta el tiempo de ejecución.

Empieza ya con la solución de seguridad de IA de Fluid Attacks
Suscríbete a nuestro boletín
Mantente al día sobre nuestros próximos eventos y los últimos blog posts, advisories y otros recursos interesantes.
Otros posts

























